Hive Overview¶
Hive is an uberfast data storage system. It uses key-value pairs to organize stored data. Datasets are stored in-memory, thereby all requests are processed at very low latencies. Hive is capable of processing a large number of requests rapidly and reliably. This technology opens new possibilities to a wide range of applications.
While the key-value storage is simple in principle, it offers an elegant and highly performing solution for a variety of use cases. These may include, but not limited to usage analytics, job queues, leader boards, game management, real-time analytics and much more. Below are a few examples describing various usages for Hive:
Real-time Analytics
Modern applications require quick data processing to make decisions, and traditional databases may not provide sufficient performance. Hive's very small latency allows streaming data to applications built for user analysis, ad-targeting, personalization, precise weather forecasts and other areas where speed matters.
Machine Learning
Whether the goal is to develop a fraud prevention system for the financial industry, deploy a virtual personal assistant, or create a real-time traffic alerts application, the Hive's data storage ecosystem provides all required data types for that.
Gaming Leader boards
When thousands of users play an online game, it is necessary to save and update data quickly, especially if players perform in-game transactions or compete for a higher score. The Hive's Sorted-Set data structure allows you to store a collection of unique score-value pairs, that can be used to link players to their current numerical state that can be a place in the leader board, the amount of earned in-game currency or even a trust score.
Hive Structure¶
Below is a summary conceptually identifying the structure of Hive in your Backendless application:
- Your application may have multiple hives.
- Each hive has a logical name that identifies it among other hives.
- Every hive is a higher-level container that consists of 5 different data storage buckets.
- Each bucket can store data of a specific data type.
- These data types are List, Map, Key-Value, Set and Sorted-Set.
- Every bucket can store multiple key-value pairs, where the value must have the structure as defined by the bucket data type.
For instance, consider the table below that highlights how these key-value pairs are structured in the system:
| Data Type |
Key |
Value |
|---|---|---|
| key-value |
"Japan" |
"Tokyo" |
| list |
"names" |
["Mike", "Bobby", "Frank", "Andrew", "Simon"] |
| map |
"fruits" |
{"Apples":0.99, "Oranges":1.19} |
| set |
"cars" |
["Sedan", "Crossover", "Coupe", "SUV"] |
| sorted-set |
"leaderboard" |
[[48,"Bob"], [32,"John"], [10,"Simon"], [3,"Jessica"]] |
Data Types¶
The Hive system supports five core data types: List, Map, Key-Value, Set and Sorted-Set. There are APIs for every data type to interact with the data stored in the corresponding bucket type. APIs provide functions that allow adding, modifying, deleting, moving, calculating, and performing other actions over data objects.
A single value in any data structure supported by Hive can be of any type. This includes strings, integers, booleans, dates, objects and arrays.
List¶
List is an unordered collection of values, and it means that values are stored in the list in the same order as they were added. Duplicate values are allowed (for a data structure that does not allow duplicates, see Set and Sorted Set).
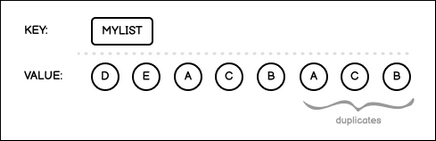
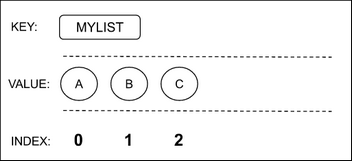
Every element in the List is located at a specific index position. Some API methods require index positions of values to modify or delete them, and some methods use index positions to add new items into a data structure. List indexes are 0-based, it means the very first element in a List has the index of 0.
For example, the value A is located at the index position 0, and the value B is at the index position 1.
Key-Value¶
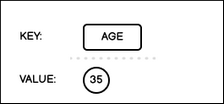
This data structure stores a single value for a key, where the keys must be unique. Keys must be strings, while values can be of any valid JSON data type. To retrieve a value for a key, use the key name in the API call.
Map¶
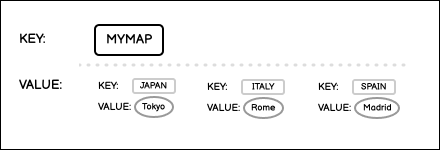
A data structure where the value for a single key is an unordered collection of key-value pairs. The keys in the collection must be unique. The values can be of any data type and mapped one-to-one for each key.
Set¶
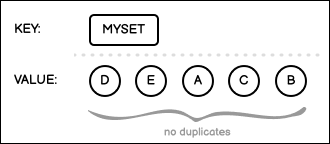
A data structure where the value for a single key is a collection of unique values. Duplicates cannot be added to a Hive bucket of this data type.
Sorted-Set¶
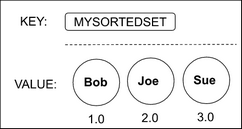
A data structure where a single key's value is a collection of unique score-value pairs. The score determines the order of items in the collection from the smallest to the largest. Values cannot contain duplicates, but at the same time the score can be the same across multiple values. If multiple sorted-set items have an identical score, then these items are ordered lexicographically.
As you can see in the example below, values are ordered by score ranging from 1.0 to 3.0.
If we insert a new item Sam with the score 1.5, the Sorted Set automatically reorders all elements within this data structure, placing Sam between Bob and Joe.

The order of elements in the sorted-set is called rank. The rank is the position of an element in the sorted-set which always starts from 0, it means the very first element in a Sorted-Set has the rank of 0. The rank of an element always depends on the current score. If the score changes, the value gets reordered in the sorted-set, and the corresponding rank also changes. In the example below you can see the rank of the elements in sorted-set:

Data Reference Scheme¶
When addressing data in a Hive, you will use a hierarchical structure that uniquely identifies a specific key and its corresponding value in the entire Hive system. In other words, every key has its own "address", which acts as an access point to the value.
Every data request goes through a base-path, that consists of the following elements:
https://xxxx.backendless.app/api/hive/[hive-name]/[bucket-type]/[key]
where:
| Argument | Description |
|---|---|
[hive-name] |
Hive name where the key in the bucket type is accessed |
[bucket-type] |
Data type within [hive-name] that should be accessed. Acceptable values are list, key-value, map, set or sorted-set. |
[key] |
Name of the key to access. |
Once a request reaches a specific key, the data stored in that key-value pair becomes accessible for modification or retrieval. For instance, consider the following request:
curl --location --request GET "https://xxxx.backendless.app/api/hive/demoHive/key-value/requestedKey"
where:
| Argument | Description |
|---|---|
demoHive |
Hive name. |
key-value |
Data type used to store information. |
requestedKey |
Name of the key to get a value. |
Endpoint URL
The xxxx.backendless.app is a subdomain assigned to your application. For more information see the Client-side Setup section of this documentation.
https://xxxx.backendless.app/api/hive/[hive-name]/[store-type]/[key]