SQL cons
Hardware
SQL databases have historically required that you scale up vertically. This meant you could only expand capacity by increasing capabilities, such as CPU, SSD, and RAM, on the existing server or by purchasing a larger, costlier one.
As your data continues to grow, you’ll invariably need to constantly increase hard drive space and require faster and more efficient machines to run newer and more advanced technologies. With this, hardware can quickly become obsolete.
Modern SQL databases may use a process called sharding. Sharding allows for horizontal scaling by separating, or partitioning, data among multiple data tables with identical schemas. Rather than storing 100,000 objects in one table, for example, sharding creates two tables with identical schemas that each store 50,000 objects, with no duplication between the tables.
Of course, utilizing a serverless hosting service such as Backendless can alleviate the scaling concern. The Backendless system is designed to manage scaling automatically for you, so that you don’t have to worry about physical server management while achieving database efficiency at scale.
Rigidity
A traditional relational model, or schema, of a SQL database has to be defined before use. Once this is done, they become inflexible, and any adjustment can become resource-intensive and difficult. Due to this, significant time should be invested in planning before putting the database into production.
With Backendless, however, developers can always modify schema even after their app is launched. New tables and columns can be added, relations established, etc., providing greater flexibility than a traditional SQL database. This makes the Backendless system well suited for early product development as you are not locked into a schema at the beginning of the development process.
Data Normalization
The goal behind the development of relational databases is to negate data duplication. There is different information for each table, and this information can be queried and connected using common values. But, when SQL databases become large, the joins and lookups needed between several tables can slow things down considerably.
To put more simply, relational databases commonly store related data in different tables. The more tables storing data needed for a single query, the more processing power is needed to complete that query without the system slowing down significantly.
Traditionally resource-intensive upgrade and scaling
As previously mentioned, vertical scaling-up of SQL databases is done by expanding hardware investment. This is costly and time-consuming to do on your own. Some organizations try to scale up horizontally through partitioning. However, this further complexity increases the resources and time expended. It will likely involve coding and require highly-skilled, well-paid developers.
Systems like Backendless, however, are designed to manage the scaling process for you automatically. This is often referred to as infrastructure as a service, or IaaS, and is far less expensive than managing infrastructure yourself. IaaS providers handle the difficult tasks of server maintenance and resource allocation for you so that you can focus on building a great product without worrying about what will happen when your database grows.
NoSQL pros
Query speed
NoSQL queries are denormalized. Therefore, with no fear of data duplication, all the needed information for a specific query is often stored together. This means that joins are not required. As a result, lookups are easier when dealing with large volumes of data. NoSQL is very fast for simple queries.
Continuous availability
For a NoSQL database, data is distributed across different regions and multiple servers, implying no single failure point. This makes NoSQL databases more resilient and stable, with zero downtime and continuous availability.
Agility
This database gives developers enough flexibility to help improve their productivity and creativity. They are not bound by rows and columns, and their schemas do not have to be predefined. They are dynamic such that they can handle all data types, including polymorphic, semi-structured, structured, and unstructured.
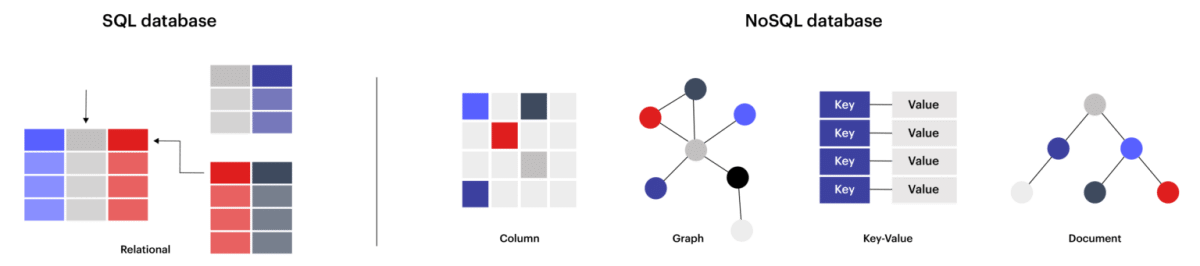 Image source
Image source
Application developers can just come in and start building a database without needing to spend effort and time on planning upfront. It allows for quick modifications when there are changes in requirements or a new data type needs to be added. This flexibility makes this database a perfect fit for companies with varying data types and constantly changing features.
Low-cost scaling
It is cost-effective to expand the capacity as a NoSQL database scales up horizontally. Instead of upgrading costly hardware, the difference with this database is that you can expand cheaply by simply adding cloud instances or commodity servers. Also, many open-source NoSQL databases offer cheap options for many companies.
NoSQL cons
No standardized language
There is no fixed language for conducting NoSQL queries. There is variation in the syntax used in querying data for different NoSQL database types. Unlike SQL, where there is only one language to learn, NoSQL has a higher learning curve. Similarly, it can be more difficult to find experienced developers with knowledge of the NoSQL system that you have implemented. Thus, it is more likely that you will need to train new hires, increasing onboarding time and cost.
Inefficiency in conducting complex queries
Querying isn’t very efficient due to the numerous data structures present in NoSQL databases. There is no standard interface to perform complex queries. Conducting simple NoSQL queries might even require programming skills due to the structure of your data. As a result, costlier and more technical staff might be needed to perform the queries. This is one of the major NoSQL limitations, particularly for less technical (i.e. no-code) developers.
A smaller number of users
Developers are now starting to use NoSQL databases more and more and are quickly becoming a growing community. However, it is still not as mature as the SQL community. Also, with fewer experts and consultants, it could be more difficult to solve undocumented issues.
Inconsistency in data retrieval
Data is quickly available thanks to the distributed nature of the database. However, it could also be harder to ensure that the data is always consistent. Sometimes, queries might not return updated data or accurate information. The distributed approach makes it possible for the database to return different values consecutively, depending on the queried server.
This is a major reason why NoSQL is not ACID-level compliant. “C” – Consistency implies that data must be consistent and valid at the beginning and completion of a transaction. Rather, many NoSQL databases are BASE compliant, where “E” signifies Eventual Consistency. NoSQL places importance on availability and speed over consistency. Inconsistency in data retrieval is one of the major drawbacks of NoSQL databases.
Conclusion – Considering your options
Both SQL and NoSQL databases are used in meeting specific needs. Depending on the goals and data environment of an organization, their specific pros and cons could be amplified.
A common misconception is that it is bad to use both technologies together; as a matter of fact, you can use both together, such that each database type play to its strengths. Many companies use both databases within their cloud architecture. Some even use it within the same application.
In the end, it is all about weighing your options and going with the preferred choice that best suits your needs.
Thanks for reading, and Happy Codeless Coding!