What is Redis?
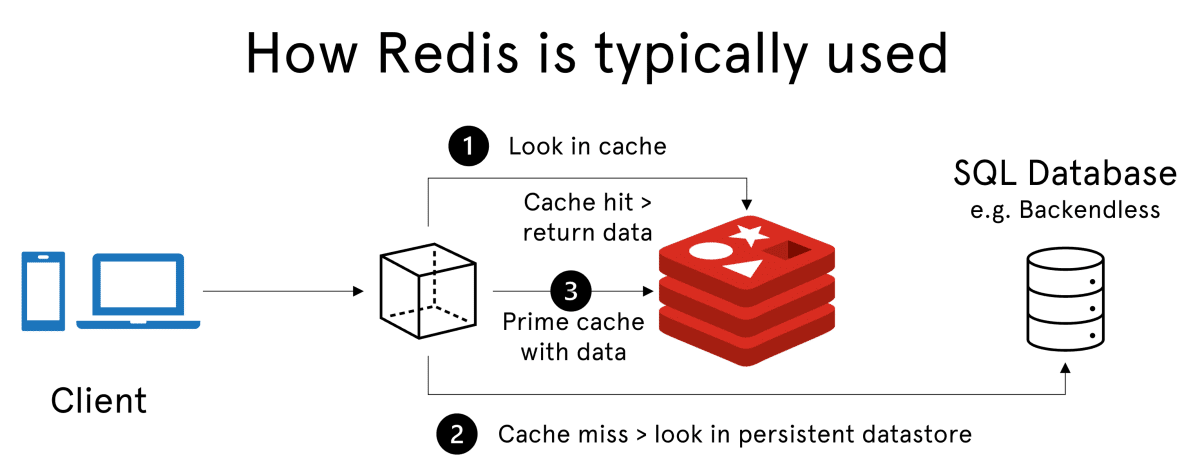
Redis is an open source in-memory data store that works really well as a cache or message broker, but it can also be used as a database when you don’t need all the features of a traditional database. It offers excellent performance, with the ability to quickly read and write data to memory. Additionally, Redis supports atomic operations, making it ideal for caching scenarios where you need fast access time.
In-memory database
An in-memory database is a type of database that stores data entirely in main memory (RAM) rather than on disk. In-memory databases are designed to provide fast access to data by leveraging the high speed of main memory, which is several orders of magnitude faster than disk storage.
In-memory databases are commonly used in applications that require fast access to large amounts of data, such as real-time analytics, online gaming, e-commerce, and social media. They are also used in applications that require high performance and scalability, as in-memory databases can handle high volumes of data and transactions without sacrificing performance.
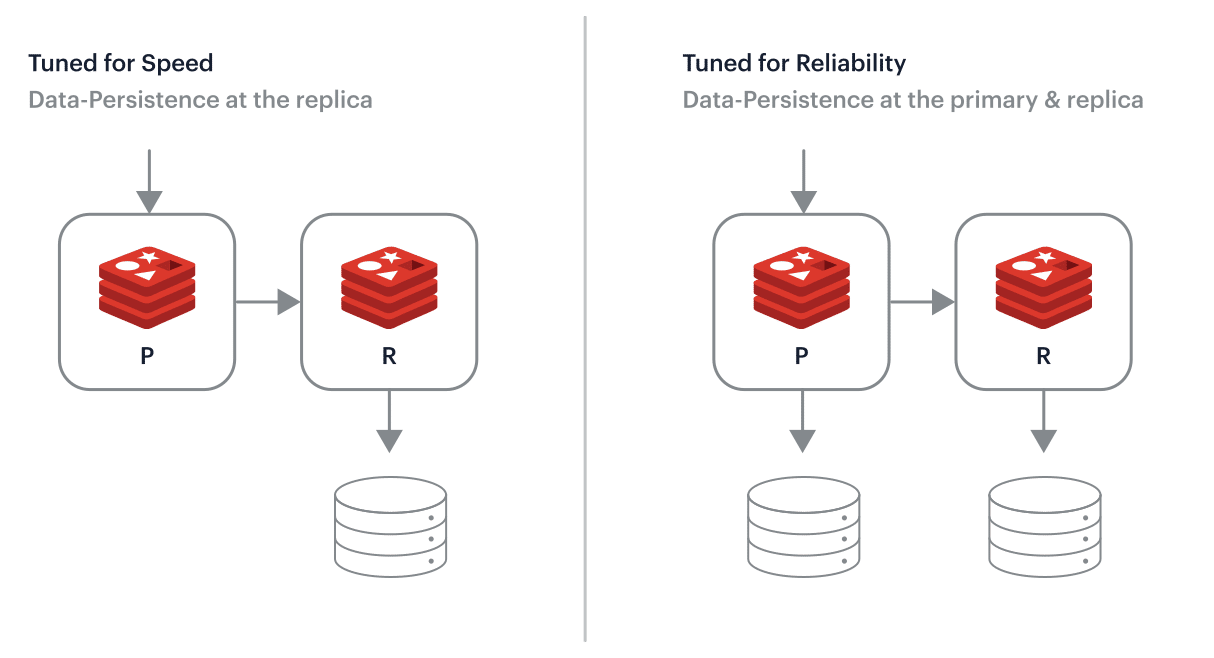
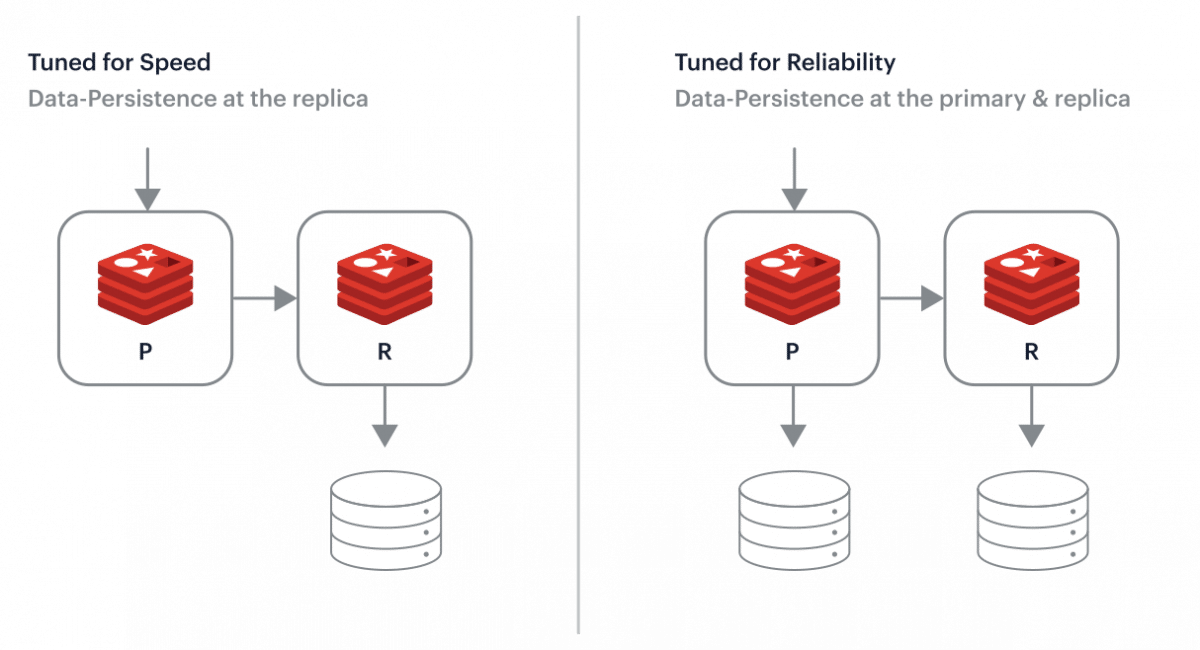
One of the main drawbacks of in-memory databases is that they are more sensitive to data loss in the event of a crash or shutdown, as the data is stored entirely in memory and is not persisted to disk. To address this issue, many in-memory databases, including Redis, provide features such as persistence and replication, which allow data to be saved to disk and replicated across multiple servers to ensure data durability and availability.
Redis persistence
Redis persistence is a feature of the Redis database that allows data to be saved to disk and restored in the event of a crash or shutdown. By default, Redis stores data in memory, which means that it is lost when the Redis server is shut down or restarted. Redis persistence enables data to be saved to disk and restored when the Redis server starts up again, ensuring that data is not lost in the event of a crash or shutdown.
Redis persistence can be configured in several ways, depending on the needs of the application. The simplest form of persistence is snapshotting, which involves periodically saving the entire Redis dataset to disk. This approach is fast and efficient, but it can result in data loss if the Redis server crashes between snapshots.
(Image source: redis.com)
Another form of persistence is append-only file (AOF) persistence, which involves saving each write operation to a log file on disk. This approach provides better durability than snapshotting, as it allows the Redis server to recreate the dataset by replaying the log file in the event of a crash. However, it can be slower and more resource-intensive than snapshotting.
Overall, Redis persistence is a valuable feature that allows data to be saved to disk and restored in the event of a crash or shutdown, ensuring data durability and availability.
What is Redis used for?
Redis is often used for caching web pages, reducing load on servers and improving page loading times. It can also be used as a message broker to facilitate communication between different parts of an application. Additionally, Redis supports transactions, making it possible to execute multiple operations atomically.
Let’s look at some specific Redis use cases:
- Real-time analytics: Applications can use Redis to store and process large amounts of data in real-time, allowing organizations to quickly analyze and visualize data to make business decisions.
- Online gaming: Gaming software can use Redis to store and manage game state, such as player profiles, game scores, and leaderboards, which allows for fast and seamless gameplay.
- E-commerce: Ecommerce apps can use Redis to store and manage data related to online shopping, such as product catalogs, user profiles, and shopping cart contents, which enables fast and efficient shopping experiences for users.
- Social media: Social apps can use Redis to store and manage data related to social media interactions, such as user profiles, friend lists, and news feeds, which allows for fast and smooth user experiences.
What are key-value pairs?
In Redis, a key-value pair is a data structure that consists of a unique key, which is used to identify the data, and a value, which is the data itself. Key-value pairs are the most basic data structure in Redis, and they are used to store and manage data in the database.
Redis supports a wide range of data types for keys and values, including strings, hashes, lists, sets, and sorted sets. This allows developers to store and manipulate a variety of data types in Redis, such as text, numbers, arrays, and complex data structures.
Redis provides a rich set of commands for working with key-value pairs, such as SET, GET, and DEL for strings, HSET, HGET, and HDEL for hashes, and LPUSH, LGET, and LREM for lists. These commands enable developers to store, retrieve, and manipulate data in Redis efficiently and easily.
Rich data structures
Data structures in Redis are collections of data that are organized and managed in a specific way to support efficient operations. For example, the string data type in Redis is a sequence of bytes that can be used to store and manipulate text or binary data. The hash data type, on the other hand, is a mapping of field-value pairs that can be used to store and manipulate complex data structures.
Each data structure in Redis has its own unique set of operations that can be performed on it, such as GET, SET, and DELETE for strings, HGET, HSET, and HDEL for hashes, and LPUSH, LPOP, and LRANGE for lists. These operations enable developers to efficiently store, retrieve, and manipulate data in Redis.
Overall, data structures in Redis are an important aspect of the framework, as they provide the underlying foundation for efficient data management and manipulation.
Chat and messaging applications
To support chat and messaging applications, Redis can be used to store and manage data related to conversations, users, and messages. For example, Redis can be used to store information about individual conversations, such as the participants and the latest messages. It can also be used to store information about individual users, such as their profile details and their list of contacts. Finally, Redis can be used to store the actual messages themselves, along with metadata such as the sender, recipient, and timestamp.
In addition to storing data, Redis can also be used to manage messaging operations, such as delivering messages to recipients, broadcasting messages to multiple recipients, and storing messages for offline users. These capabilities make Redis a powerful tool for building chat and messaging applications that are fast, scalable, and reliable.
Session store
Session store is a mechanism for storing user session data in a web application. In a Redis session store, session data is stored in a Redis database, which is a fast, in-memory data structure store that can be used as a cache, database, and message broker.
In a Redis session store, session data is stored in a Redis database as key-value pairs, where the key is a unique identifier for the session and the value is the session data itself, which may include information such as the user’s login status, preferences, and shopping cart contents.
The benefits of using a Redis session store include improved performance and scalability, as Redis can store and retrieve session data quickly and efficiently, even when dealing with large amounts of data. Additionally, Redis allows session data to be shared across multiple servers, which can be useful in a load-balanced environment.
What are the benefits of Redis?
One of the main advantages of using Redis for caching is its fast read and write speeds. Redis can handle millions of operations per second, which allows it to serve webpages faster than traditional databases. It also offers excellent support for transactions, allowing applications to perform multiple operations atomically. Additionally, Redis supports the use of pub/sub channels for fast data sharing between applications.
Redis is also highly scalable and can be deployed across multiple machines for high availability. This makes it ideal for distributed systems that need to quickly process large amounts of data.
For example, Redis can be used to store session information in a distributed system and provide quick access to that data across multiple servers. This makes Redis incredibly powerful gaming applications because it can quickly and efficiently share data across multiple nodes in near real time.
In addition to excellent performance, another advantage of Redis is that it offers a number of features that are not available in traditional databases. These include pub/sub, which allows you to publish messages and subscribe to them, as well as transactions and Lua scripting. These features can be used to build powerful applications that are not possible with traditional databases.
What is Lua scripting?

Lua scripting is a technique for writing and executing scripts in the Lua programming language within a host application. Lua is a lightweight, versatile, and embeddable scripting language that is widely used for writing scripts that can be run within other applications.
In the context of Redis, Lua scripting allows developers to write and execute scripts that manipulate data stored in a Redis database. Redis provides a built-in scripting engine that supports Lua, which allows developers to write scripts that can be executed within the Redis server.
One of the main advantages of Lua scripting in Redis is that it allows developers to write complex operations that can be executed atomically and in a single step. This means that the scripts can manipulate data in Redis without interference from other operations, ensuring data consistency and integrity.
Overall, Lua scripting is a powerful and flexible tool that can be used within Redis to write and execute complex operations on data stored in the database.
What are the drawbacks of using Redis?
Like any technology, Redis has some drawbacks that should be considered when deciding whether to use it in a particular application.
One of the main drawbacks of Redis is that it stores data entirely in memory, which means that it can be sensitive to data loss in the event of a crash or shutdown. To address this issue, Redis provides features such as persistence and replication, which allow data to be saved to disk and replicated across multiple servers. However, these features can add complexity and overhead, which may not be suitable for all applications.
Another drawback of Redis is that it is a single-threaded system, which means that it can only process one command at a time. This can limit the performance and scalability of Redis in applications that require high concurrency and parallelism. To address this issue, Redis provides clustering and sharding features that allow data to be distributed across multiple servers, but these features can be complex to set up and manage.
Closing
Overall, Redis is an excellent tool for caching web pages and reducing server load, but it also has some features that can be used to create powerful distributed applications. It’s fast, scalable, and supports advanced features like Pub/Sub and Lua scripting. However, it does have some drawbacks such as the need for additional memory and the lack of ACID compliance or support for joins. Take all this into consideration before using Redis in your project.
Alternately, Backendless offers Hive. Built on Redis, Hive provides the benefits of Redis with the vast feature set of Backendless. In addition to the advantages of Redis, Hive offers all of the capabilities of a traditional SQL database by integrating with Backendless Database. With Backendless, you are able to work with data in a wide variety of ways to achieve your application’s needs.