Data Types
The Hive system supports five core data types: List, Map, Key-Value, Set, and Sorted Set.
There are APIs for every data type to interact with the data stored in the corresponding bucket type. APIs provide functions that allow adding, modifying, deleting, moving, calculating, and performing other actions over data objects.
A single value in any data structure supported by Hive can be of any JSON data type. This includes strings, integers, booleans, dates, objects and arrays.
List
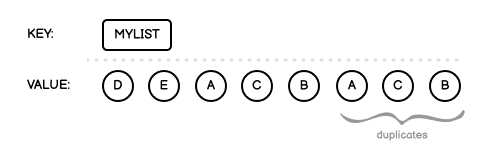
List is an unordered collection of values, and it means that values are stored in the list in the same order as they were added. Duplicate values are allowed (for a data structure that does not allow duplicates, see Set and Sorted Set).
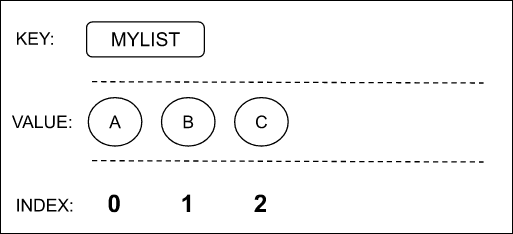
Every element in the List is located at a specific index position. Some API methods require index positions of values to modify or delete them, and some methods use index positions to add new items into a data structure. List indexes are 0-based, meaning the very first element in a List has the index of 0.
For example, the value A is located at the index position 0, and the value B is at the index position 1.
Key-Value
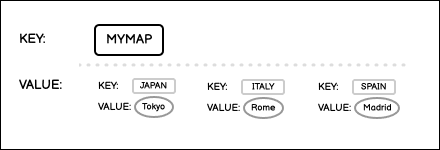
The Key-Value data structure stores a single value for a key, where the keys must be unique. Keys must be strings, while values can be of any valid JSON data type. To retrieve a value for a key, use the key name in the API call.

Map
Map is a data structure where the value for a single key is an unordered collection of key-value pairs. The keys in the collection must be unique. The values can be of any data type and mapped one-to-one for each key.
Set
Set is a data structure where the value for a single key is a collection of unique values. Duplicates cannot be added to a Hive bucket of this data type.
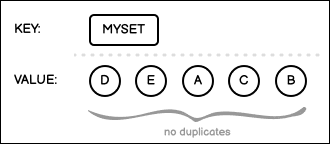
Sorted Set
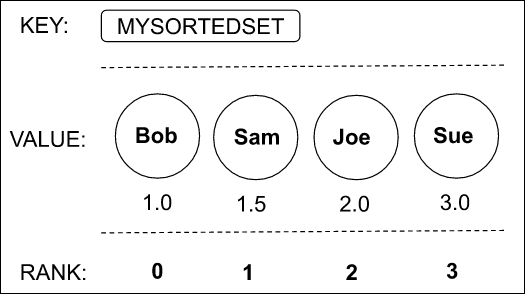
Sorted Set is a data structure where a single key’s value is a collection of unique score-value pairs. The score determines the order of items in the collection from the smallest to the largest. Values cannot contain duplicates, but at the same time the score can be the same across multiple values. If a few sorted-set items have an identical score, then these items are ordered lexicographically.
As you can see in the example below, values are ordered by score ranging from 1.0 to 3.0.
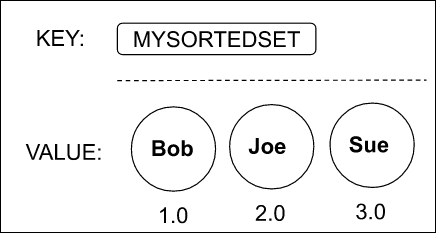
If we insert a new item Sam with the score 1.5, the Sorted Set automatically reorders all elements within this data structure, placing Sam between Bob and Joe.

The order of elements in the sorted-set is called rank. The rank is the position of an element in the sorted-set which always starts from 0, meaning the very first element in a Sorted Set has the rank of 0. The rank of an element always depends on the current score. If the score changes, the value gets reordered in the sorted-set, and the corresponding rank also changes. In the example below you can see the rank of the elements in Sorted Set: