The CSV/Excel plugin provides a complete set of functionality to transfer data between Database tables or collections of data and CSV files. This means the CSV plugin can generate CSVs from your database queries and can import data into your database from CSV files. Additionally, the plugin supports bidirectional data flow between CSV and collections of objects. The API is very versatile and lets you control all aspects of the CSV parsing or generation, including column naming, delimiters, wrapping data into quotes, header rows, etc. See below for information about installing the plugin and using its APIs.
Feature
CSV to/from Database
Marketplace Product

How It Works
The CSV/Excel plugin is installed as an API service. Once installed, the API service provides methods (endpoints) that perform data transformations from or to a CSV file. The methods/endpoints can be used using the REST API or from a native SDK. Additionally, the APIs are available as Codeless blocks.
Installation Instructions
- Login to Backendless Console and select your app. Open the Marketplace screen, select the API Services section and install “CSV/Excel Plugin” from the Backendless marketplace.
- To verify the installation, click the Business Logic icon in Backendless Console and confirm the CSV Adapter API service appears in the list of services.
Using the API
The API supported by the CSV/Excel plugin can be used either via REST, using a Backendless SDK, or with Codeless. To use the API with an SDK, generate the client-side library for the API as shown below:
- Click the Business Logic icon in Backendless Console and select the CSVAdapter API service.
- Click the Download Client SDK icon as shown below (the icon is shown in bright green color):
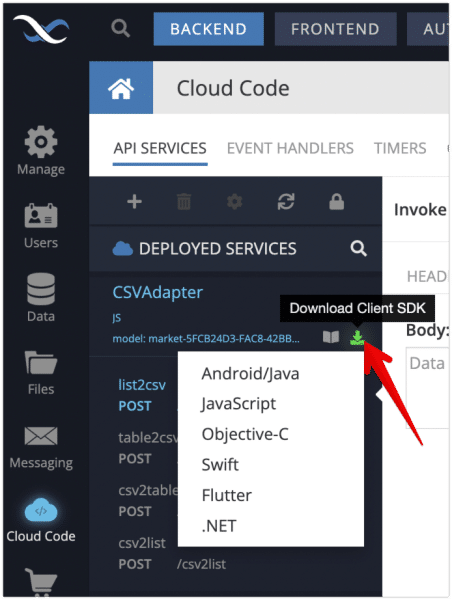
- Select the language of your choice to download the client SDK generated specifically for the CSVAdapter service. The SDK includes all the methods provided by the CSV/Excel plugin.
In case a language you would like to use does not show up in the list, you can still use the plugin using its REST API.
Table to CSV – table2csv
This operation exports a customizable dataset from a table into a CSV file. You can export data from specific columns (properties) and/or specific records (with a where clause). Additionally, you can export either a specific block/page of data or the entire data set. The CSV file can be created as new or you can append the export to an existing CSV file. The operation has four parameters:
filePath– String value. Required. A path to a CSV file located in the Backendless File storage of your app. The database table data will be exported into the specified file. The file is created if doesn’t exist. You can append to an existing file using the"append"option in thecsvOptionsparameter. If the value does not reference a directory and specifies only the file name, the file is created/updated in the root directory of your file storage.tableName– String value. Required. The name of a database table or a view from where the data will be exported.tableOptions– Object value. Optional. Configuration options to identify a subset of records fromtableName. For more information see the tableOptions Structure below.csvOptions– Object value. Options. Configuration options to control the created CSV output. For more information see the csvOptions Structure below.
Return value
The method returns a URL for the CSV file created (or updated) by the operation.
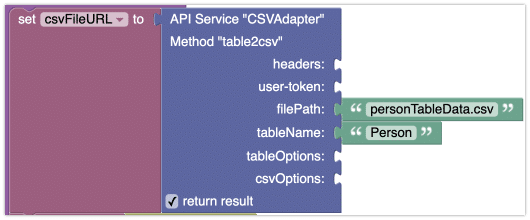
Codeless usage
The Codeless logic below illustrates the basic usage of the API:
tableOptions Structure
Parameters in this structure help you select database records that fit specific criteria. All individual parameters are optional.
where– String. Backendless where clause. The API will export only the records that match the where clause condition.properties– An array/list of the column names to include in the export. By default, all columns from the source table are included. By usingproperties, only the specified column names will be included in the export. In addition to property names, you can specify aggregate and database functions. You can use related column names. Use the dot-notation to identify columns of a related-of-a-related table. When referencing a related column for a one-to-many relation, you will get multiple exported records for the same parent record. The system exports a separate record for each combination between the parent and child records. To prevent this behavior, use thedistinctparameter.excludeProps– An array/list of the column names to exclude from the export. Ifpropertiesis not set, all column names from the source table are included. You can exclude specific column names usingexcludeProps.sortBy– An array/list of string values. Each value in the list must be a name of a column to sort the resulting export by. By default, the sorting order is ascending, to request the descending order, add “DESC” to the name of the column (separated with the space character).distinct– Boolean value, default isfalse. When set totrue, the resulting export will exclude duplicate records based on theobjectIdvalue. This may be needed when a property name from a related one-to-many table is added to thepropertiesparameter.relations– An array/list of related column names. When a related column name is added to therelationsproperty, the related objects for the specified relation column are added to the export in the JSON format. These JSON objects become individual CSV values for a separate column dedicated to the related table.relationsDepth– A numeric value representing the depth of the related objects to include in the scope of the export operation. For more information about relation depth, see the Backendless API documentation.groupBy– An array/list of column names to group the export by. Grouping makes more sense when you use an aggregate function in thepropertiesparameter.having– A string value containing a having clause used by aggregate functions. Should be used for result filtering when an aggregate function is used in thepropertiesparameter. For additional information see Aggregated Data Filtering in Backendless API documentation.fileReferencePrefix– A string value containing a prefix added to the file paths stored in the database columns of theFILEREFERENCEdata type. When the file path value in the database is for a file stored in the Backendless file storage, it is in a relative format starting with the root directory. By default, the Backendless database completes the path to make it a full URL when an object is retrieved for export. UsingfileReferencePrefix, you can set a specific prefix (such as a domain name) that will be used to build an absolute file URL.pageSize– An integer value. Specifies how many records to include in the export. If nopageSizeis set,offsetwill be ignored and all records from the database are exported.offset– An integer value. Assuming the very first record in the data set to be exported has an index of 0, this parameter sets the index of the first record to be actually exported. The number of records to export is set with thepageSizeparameter. If thepageSizevalue is not set, theoffsetparameter is ignored.columnsMapping– Object. Provides instructions for how table columns should be mapped to the “columns” in the CSV file. The object should use table column names as keys and the assigned column in CSV as value. For example:{ "amount":"order amount", "name":"customer name" }With the mapping above, the
"amount"and"name"columns from the database table will be named"order amount"and"customer name"respectively in the export CSV.
csvOptions Structure
Parameters in this structure can configure various aspects of the export CSV. All parameters are optional.
append– A boolean value (trueorfalse). When set totrue, the exported records are appended to the CSV file if it already exists.delimiter– A string value. Sets the field delimiter. Can be one or multiple characters. Default is the comma character.escape– A string value, must be a single character. Used for escaping double quotes in the resulting CSV. The default value is".header– A boolean value (trueorfalse). Adds a header row in the CSV. The row contains the names of the columns.quote– A single character or an empty string. The value is used to quote/wrap string values from the database. String value wrapping is controlled by thequoted,quoted_empty, andquoted_string. The defaultquoteparameter value is".quoted_string– A boolean value (trueorfalse). When set totrue, unconditionally wrap/quote into the quote character all values of type string; The default value isfalse.quoted– A boolean value (trueorfalse). When set totrue, unconditionally wrap/quote into thequotecharacter all the non-empty values of type string; The default value isfalse.quoted_empty– A boolean value (trueorfalse). When set totrue, unconditionally wrap/quote into the quote character all empty values of type string; The default value isfalse.record_delimiter– A string value. The value is used to delimit record rows. Delimiting rows means how rows end or what separator/delimiter is used to identify the end of a row. Supported special values are"auto","unix","mac","windows","ascii","unicode"; The default value is"auto"(discovered in the target file or"unix"if the target file is created by the operation).eof– A boolean value (trueorfalse). When set totrue, adds the value of"record_delimiter"on the last line of the CSV file. The default istrue.
Examples
Consider the following data table:
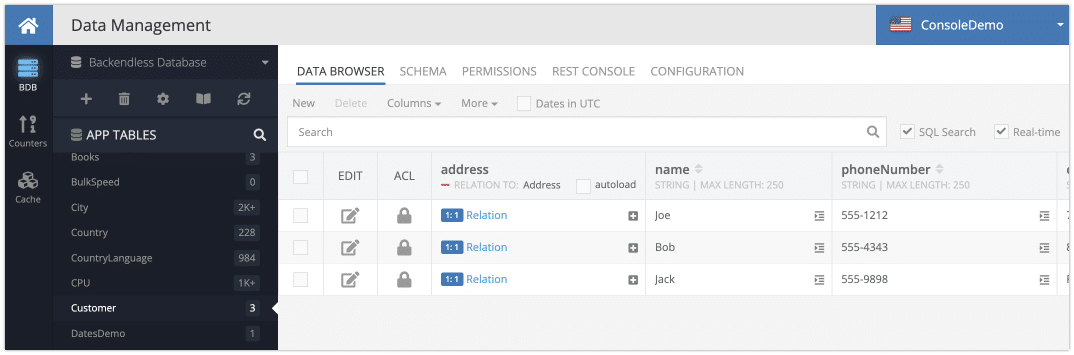
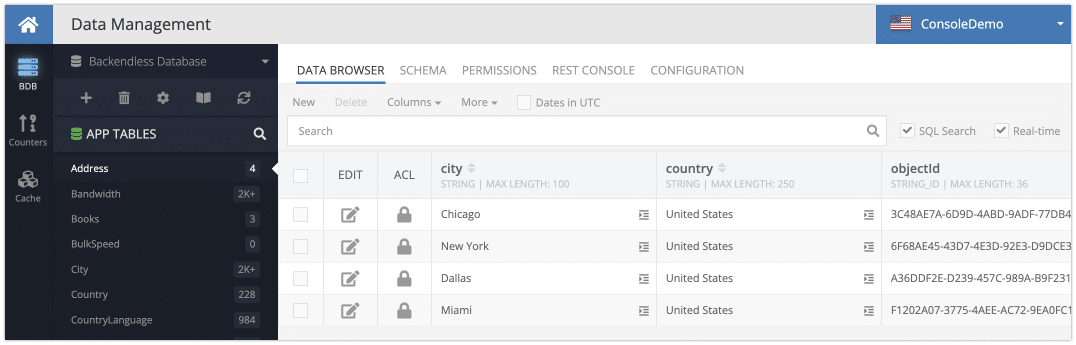
The related Address table has the following structure and data:
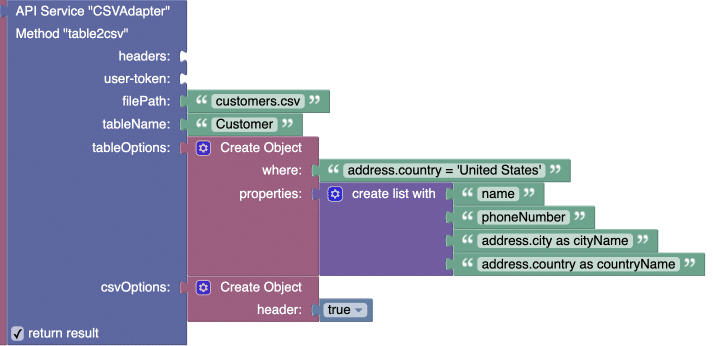
Example 1
The example below demonstrates the following capabilities:
- Exporting records that match a query
address.country = 'United States'. Notice the query references a column in a related table - Exporting specific columns/properties. Notice two of the columns come from the related table
- Adding a header in the resulting CSV
A CSV created in this example has the following data and the structure:

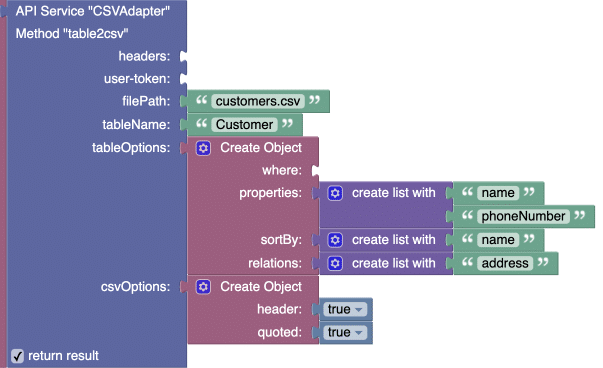
Example 2
The example below demonstrates the following capabilities:
- Exporting specific columns/properties.
- Exporting related records – notice the
relationsparameter. - Sorting the exported records – notice the
sortByparameter. - Adding a header in the resulting CSV
- Configuring the string values to be unconditionally surrounded by (wrapped into) double quotes.
A CSV created in this example has the following data and the structure:
"name","phoneNumber","address","objectId"
"Bob","555-4343","{""country"":""United States"",""city"":""Dallas"",""created"":1626484471000,""___class"":""Address"",""ownerId"":null,""updated"":1642509292000,""objectId"":""A36DDF2E-D239-457C-989A-B9F2319A58BC""}","8D79BA7D-ACE3-47DC-9D90-B5985CDDD363"
"Jack","555-9898","{""country"":""United States"",""city"":""New York"",""created"":1628465921000,""___class"":""Address"",""ownerId"":null,""updated"":1642509288000,""objectId"":""6F68AE45-43D7-4E3D-92E3-D9DCE37F0EA3""}","FC584FF8-E44B-408D-B9F4-F7CF387CD538"
"Joe","555-1212","{""country"":""United States"",""city"":""Miami"",""created"":1642509300000,""___class"":""Address"",""ownerId"":null,""updated"":1655507848005,""objectId"":""F1202A07-3775-4AEE-AC72-9EA0FC1BC54C""}","765EF32B-A715-4C54-84D6-EB1E8B622121"
CSV to Table – csv2table
This operation imports data from a CSV file into a database table in Backendless. The input CSV file is referenced with a URL. The method processes the entire CSV file, however, you can specify a range of CSV rows to import. The operation has four parameters:
csvURL– String value. Required. A URL to a CSV file to import data from.tableName– String value. Required. The name of a database table where the CSV records will be imported to.tableOptions– Object value. Optional. Configuration options for the import process. For more information see the tableOptions Structure below.csvOptions– Object value. Options. Configuration options to control the CSV parsing and processing process. For more information see the csvOptions Structure below.
Return value
The method returns a collection of objectId values for the records added to the table. If the imported records already have the objectId column, the CSV/Excel Plugin will recognize and use the values.
Codeless usage
The Codeless logic below illustrates the basic usage of the API:
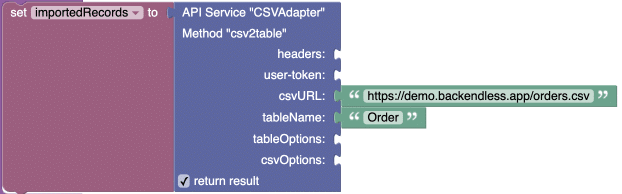
tableOptions Structure
Parameters in this structure help you select database records that fit specific criteria. All individual parameters are optional.
columnsMapping– Object. Provides instructions for how the CSV columns should be mapped to the columns in the database table. The object should use CSV column names as keys and the table column names as values. For example:{ "order amount":"amount", "customer name":"name" }With the mapping above, values from the
"order amount"and"customer name"CSV columns will be written to the"order"and"name"columns in the database.
csvOptions Structure
Parameters in this structure can configure various aspects of the export CSV. All parameters are optional.
columns– A list of column names to assign to the CSV values. When the CSV file does not have the header row with the names of the column names, this property can be used to provide the column names as string values. The order of the names in the list must match the order of the values in the individual CSV rows. The property may also have a boolean value oftrueorfalse. This is used in combination with thegroup_columns_by_nameproperty.group_columns_by_name– A boolean value (trueorfalse). When set totrue, different columns with the same name will be grouped together and saved as JSON arrays. The column in the database must be of theJSONtype.delimiter– A string value. Sets the CSV field delimiter. Can be one or multiple characters. Default is the comma character.encoding– A string value. Sets the encoding to use when reading the CSV file. The default value isutf8.escape– A string value, must be a single character. Used for escaping double quotes in the source CSV. The default value is".from_line– A numeric value. Indicates row index from which the processing should start. The first row has an index of 1.to_line– A numeric value. Indicates an index of the row where the processing should stop (excluding the identified row). The first row has an index of 1. If the value is greater than the maximum number of rows, the parameter is ignored.ltrim– A boolean value (trueorfalse). If set totrue, CSV processor ignores whitespace immediately following the delimiter (i.e. left-trim all fields). Does not remove whitespace in a quoted field (a field wrapped in quotes). The default value isfalse.rtrim– A boolean value (trueorfalse). If set totrue, CSV processor ignores whitespace immediately preceding the delimiter (i.e. right-trim all fields). Does not remove whitespace in a quoted field (a field wrapped in quotes). The default value isfalse.trim– A boolean value (trueorfalse). If set totrue, CSV processor ignores whitespace around the delimiter, effectively yielding the same result as bothltrimandrtrimset totrue. Does not remove whitespace in a quoted field (a field wrapped in quotes). The default value isfalse.quote– A single character or an empty string. The value is used to quote/wrap string values from the database. String value wrapping is controlled by thequoted,quoted_empty, andquoted_string. The defaultquoteparameter value is".record_delimiter– A string value. One or multiple characters used to delimit records; If the value is not set, the CSV processor uses the auto-discovery mode. Supported auto-discovery methods are Linux ("\n"), Apple ("\r") and Windows ("\r\n") row delimiters.
Example
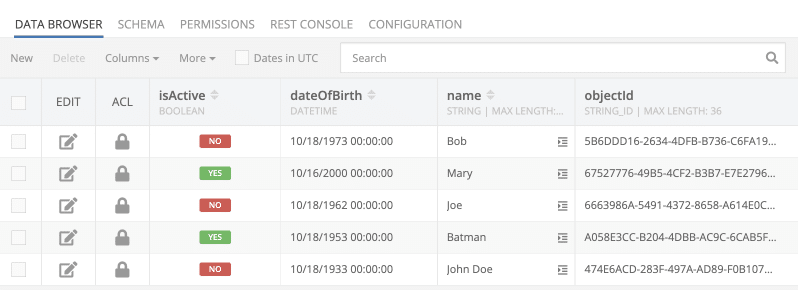
The source CSV has the following data and the structure:
created,name,dateOfBirth,isActive,ownerId,updated 1586020674000,Joe,-227386800000,0,"",1603078295000 1586022127000,Bob,119768400000,0,"",1603078273000 1585964547000,Batman,-511380000000,1,"",1658270125079 1585533585000,John Doe,-1142532000000,0,"",1603078328000 1586022127000,Mary,971672400000,1,"",1658270124142
The Codeless login below uses the plugin API to import the CSV into the Person table:
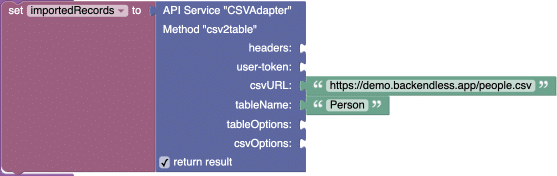
Below is the database table after the data has been imported from the CSV file: