Importing Data to Backendless¶
Overview¶
This chapter is dedicated to outlining the various methods supported by Backendless for importing data into the Backendless Database. These methods are designed to offer flexibility and cater to different user needs and data formats. Access to the data import features is streamlined through the Backendless Console, under the Manage > Import section for the application you have selected.
Upon accessing the Import section in the console, you will be presented with several options to choose from, each catering to different data import needs:
- App Zip: This option allows for the import of an entire application package in a zip file, making it easy to migrate or replicate application settings and data.
- App Settings (JSON): For a focused import of application settings, this option lets you upload a JSON file containing your app's configurations.
- Data Tables (CSVs): Ideal for bulk data import, this option supports uploading CSV files to populate your database tables with records.
- Firebase Users: Specifically designed for migrating user accounts from Firebase, this option facilitates a seamless transition for user accounts into the Backendless Database.
- AirTable Data: Catering to users migrating from AirTable, this option ensures that your AirTable data can be imported directly into Backendless, maintaining the integrity and structure of your data.

These import options are part of Backendless's commitment to providing a versatile and user-friendly database management experience, ensuring that regardless of where your data is currently stored, there's a straightforward path to bringing it into the Backendless ecosystem.
App Zip¶
Importing your application's architecture and data into the Backendless database can be efficiently achieved through the App Zip option. This feature is specifically tailored for .zip files generated via the Backendless Export process, allowing for a seamless transition of your application data into a new or existing Backendless project.
When you choose to export your application components, the generated .zip file can be customized to include any combination of the following elements:
- Application Settings: Configurations and settings that dictate how your application functions. This is primarily the information available on the Manage > App Settings screen of your source Backendless application.
- Database Schema Definition (without data): The structure of your database, including table definitions and relationships, but excluding the actual data.
- Database Schema with Data: A complete export that encompasses both the database's schema and the data within it, applicable to tables and views alike.
For a comprehensive export tailored to your needs, visit the Manage > Export section within the Backendless Console. This area provides detailed instructions on customizing your export, ensuring you can efficiently import the necessary components into Backendless with the "App Zip" option.
App Settings (JSON)¶
This option offers a streamlined approach for importing application settings into your Backendless application. This feature is available both as part of the comprehensive "App Zip" import described above and as a standalone option for those looking to specifically migrate application settings without other components.
To utilize this option, your settings should be prepared in a JSON formatted text file. Manual creation of this file is not advised due to the complexity and potential for errors in formatting. Instead, it's recommended to generate this JSON file through the Export feature of an existing Backendless application that already encompasses the desired settings. This ensures the exported JSON file accurately reflects the required configuration for your application.
By exporting the settings from an existing application, you can seamlessly import them to another project, maintaining consistency across your Backendless applications or facilitating easy setup of new projects with preferred configurations.
Data Tables (CSV)¶
The Data Tables (CSV) option in Backendless provides a flexible and straightforward method for importing data into your application's database. This feature supports the upload of one or multiple CSV files, where each file is mapped to a distinct database table. This section outlines the process and considerations for utilizing CSV files for data import.
Each CSV file you import corresponds to a single database table. If the targeted table does not already exist within your Backendless database at the time of import, it will be automatically created using the file's name. A CSV file can be structured to include just the schema definition - that is, the columns and their configurations - or it can encompass both the schema definition and the actual data records.
Consider a file named Product.csv with the following data:
| price |
productName |
|---|---|
| 599 |
iPhone |
| 899 |
Surface Pro |
| 399 |
XBOX One |
| 1200 |
MacBook |
The raw CSV format of the above table would look like this:
price,productName
599,iPhone
899,Surface Pro
399,XBOX One
1200,MacBook
To initiate the import process, click on the "Choose Files..." button adjacent to the Data Tables (CSV) option and navigate to the desired file on your computer. If you are importing multiple files, after selecting the first file, an "ADD MORE" button will become available, allowing you to include additional CSV files in your import batch.
Backendless utilizes a unique formatting approach for the header row in CSV files to facilitate data type configuration. This format allows for a detailed description of each column's data type. Although a deeper exploration of this format is reserved for later in this chapter, it's important to initially recognize that the header row in the provided example simply lists column names without specifying data types. When importing CSV files into Backendless without explicit data type information for each column, a critical step within the Backendless Console involves manually assigning data types to those columns. This process ensures that the imported data is accurately interpreted and stored within your Backendless database, maintaining the integrity and effectiveness of your application's data management.
Upon initiating the import via the IMPORT button, the Backendless Console displays a dedicated interface for this data type assignment (see the screenshot below). This interface is designed to guide users through the process, providing a straightforward method for specifying the appropriate data type for each column based on the data contained within the CSV file. This step is essential, especially when the imported file's header row includes only column names without any data type descriptors, ensuring that each piece of data is correctly categorized and utilized within your application.
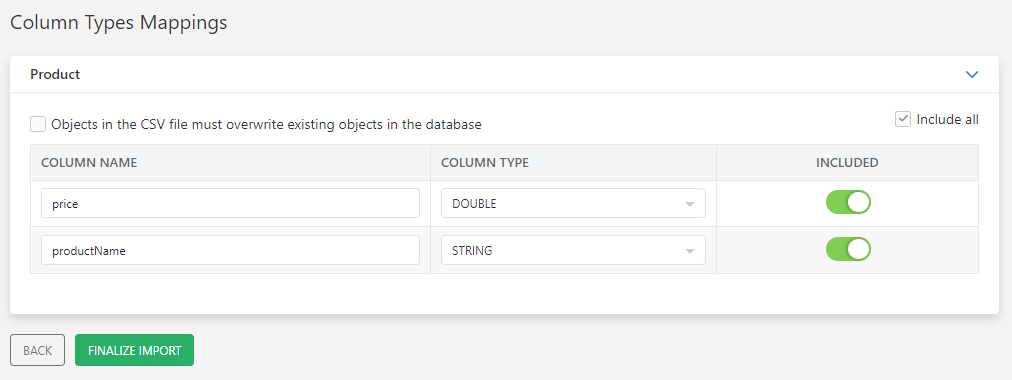
The Column Types Mappings screen allows you to select a data type for each column within your imported data. This feature is crucial for ensuring that the data within your application is accurately represented and managed. Should you import multiple CSV files simultaneously, the console will prompt you with a similar data type selection form for each file, ensuring consistency and precision across your entire dataset. Selecting the correct data type for each column is a pivotal decision in the import process. This is because only certain data types can be modified after the initial import, underscoring the importance of this step. For example, with a file like Product.csv, it's essential to assign data types that reflect the content of each column accurately. This involves specifying DOUBLE for numeric values and STRING for textual data, as illustrated in the image above.
Additionally, the Backendless Console provides the flexibility to manage which columns are imported by utilizing the INCLUDED toggle. Should you decide a particular column is unnecessary for import, you can easily exclude it by clicking the toggle, switching its state to "off". This feature offers precise control over the data you choose to incorporate into your Backendless database, ensuring that only relevant information is added.
After finalizing the data type selections for your columns, you will click the Finalize Import button to proceed. Backendless then initiates the data import as an independent, asynchronous operation. The time it takes for this process to complete can vary, largely depending on the volume of data being imported. Upon completion, Backendless will notify you of the import's status through an email sent to the email address associated with your developer account.
For the file shown above, the imported data in Backendless will appear in the Data section of the console:
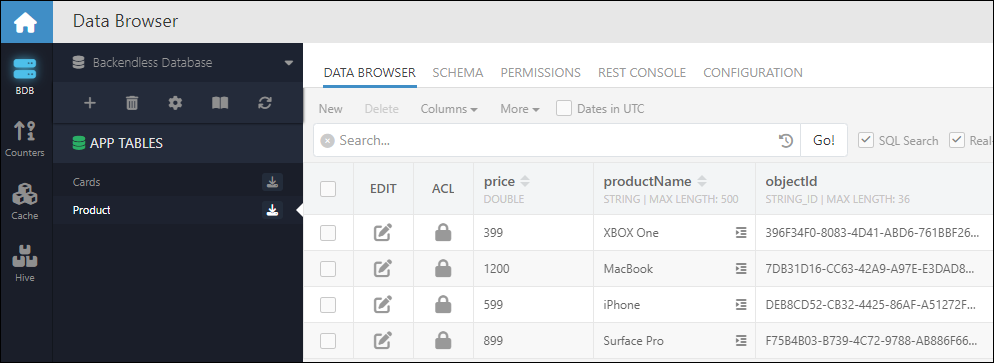
Please note, during the import process, Backendless automatically appends an objectId column to your data, assigning a unique identifier to each record. Additionally, created and updated columns are introduced to track the timestamps of when records are initially stored and subsequently modified in the database, respectively. Should your data necessitate custom identifiers, you can add a column named objectId within your CSV file. However, it is imperative that this column contains unique values for each record to maintain data integrity and avoid conflicts. For instance, your CSV might look like this:
price,productName,objectId
599,iPhone,1
899,Surface Pro,2
399,XBOX One,3
1200,MacBook,4
Data Type/Column Configuration¶
Backendless provides a robust framework for configuring the columns and data imported via CSV files, offering an array of optional configuration properties. These properties enhance the flexibility and precision of how data is handled within your Backendless database. To utilize these configuration options, they should be included directly in the CSV file's header row, adhering to one of the the following syntaxes:
Simplified Format:
ColumnName(type)
Extended Format:
"ColumnName({ Config parameters in the JSON format})"
Important
It's crucial to note the significance of double quotes within this format. The initial double quote functions as an escape character for the subsequent double quote, ensuring the JSON string is correctly interpreted.
Below is a complete declaration of the Extended version:
"ColumnName({""constraints"":[""NN"",""IDX""],""type"":""STRING"",""dataSize"":300,""validator"":""^[a-zA-Z]+$"",""defaultValue"":""SomeValue"",""dynamicProps"":{""description"":""Some description""}})"
The entire declaration in a CSV file must be in a single line, however, to enhance readability, here's a broken-down version of the same declaration:
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""TYPE NAME"",
""validator"" :""^[a-zA-Z]+$"",
""defaultValue"" :""SomeValue"",
""dynamicProps"" :{""description"":""Some description""
}})"
where:
| Argument | Description |
|---|---|
""constraints"" |
An optional JSON array specifying column constraints such as:""NN"" (Not Null): Ensures the column cannot be empty.""UQ"" (Unique Value): Guarantees all column values are unique. Cannot be used with defaultValue.""IDX"" (Indexed): Instructs the database to index the column, enhancing performance for queries that filter or search based on this column. |
""type"" |
Specifies the data type, which must be set to ""STRING"". |
""validator"" |
An optional regex pattern for custom validation rules, ensuring data integrity upon insertion or update. |
"defaultValue" |
An optional default value for the column, automatically applied when new records are added without a specified value for this column. If the ""UQ"" constraint is specified, the defaultValue parameter must not be present. |
"description" |
Provides an optional textual description of the column's purpose or significance, aiding documentation and understanding without affecting server behavior or API functionality. |
The section that follows will detail a comprehensive list of all supported data types alongside their respective configuration parameters. This guide is designed to empower you with the knowledge to effectively tailor your data import process, ensuring that your Backendless database aligns precisely with your application's requirements.
STRING¶
The STRING data type is designed for storing alphanumeric data, with a maximum allowable length of up to 500 characters. This flexibility makes it suitable for various textual data, such as names, addresses, or any other type of string data that fits within the length constraint. Below are the formats for declaring a STRING type column during the CSV import process.
For a straightforward declaration without additional constraints or configurations, the format is as follows:
ColumnName(STRING)
The extended version of the supported syntax is (make sure the entire declaration in a CSV file is in a single line).
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""STRING"",
""dataSize"" :300,
""validator"" :""regex"",
""defaultValue"" :""SomeValue"",
""dynamicProps"" :{""description"":""Some description""
}})"
All configuration parameters are documented above, except ""dataSize"" which applies only to the STRING data type:
| Argument | Description |
|---|---|
""dataSize"" |
An optional parameter indicates the maximum character length for column values, with a cap of 500 characters. |
Sample CSV - City.csv:
"cityName({""type"":""STRING"",""dataSize"":100})"
Dallas
San Francisco
New York
STRING_ID¶
The STRING_ID data type in Backendless is specifically tailored for columns that contain unique identity values for records during the CSV import process. This data type is crucial for designating a column, named objectId, to store unique identifiers for each record. These identifiers can be either numerical or string values, allowing for a diverse range of unique ID formats. The defining characteristic of the objectId column, marked with the STRING_ID data type, is the requirement for uniqueness - no two records within the CSV file can have the same ID, ensuring each record's identifier is distinct.Assigning a unique identifier to each record is optional. If the STRING_ID values are not provided, Backendless will automatically generate unique record identifiers.
Column declaration format:
objectId(STRING_ID)
Sample CSV - City.csv:
"cityName({""type"":""STRING"",""dataSize"":100})",objectId(STRING_ID)
Dallas,1
San Francisco,2
New York,3
INT¶
The INT data type is tailored for representing whole (integer) numeric values in the Backendless database, making it ideal for data that does not require decimal precision. Below are the formats to declare an INT type column within your CSV import files, ranging from simple to more complex configurations.
For basic use without additional specifications, the format is:
ColumnName(INT)
To incorporate constraints, validation, and other configurations, the extended format should be used as follows:
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""INT"",
""validator"" :""regex"",
""defaultValue"" :""SomeValue in quotes"",
""dynamicProps"" :{""description"":""Some description""}
})"
See the parameter descriptions in the general section above.
Sample CSV - City.csv:
cityName(STRING),objectId(STRING_ID),"Population({""constraints"":[""NN""],""type"":""INT""})"
Dallas,1,1288000
San Francisco,2,815201
New York,3,8468000
DOUBLE¶
The DOUBLE data type in Backendless is designed for storing numerical values with decimal points, offering precision that is not available with the INT data type, which is limited to whole numbers. This distinction makes DOUBLE ideal for a wide range of applications, such as financial calculations, scientific measurements, or any other scenario where fractional values are crucial.
For a straightforward use case that doesn't require additional specifications, the declaration format is:
ColumnName(DOUBLE)
To include more complex configurations such as constraints, validation for decimal values, and other specifics, the extended format is utilized as follows:
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""DOUBLE"",
""validator"" :""regex"",
""defaultValue"" :""SomeValue in quotes"",
""dynamicProps"" :{""description"":""Some description""}
})"
See the parameter descriptions in the general section above.
Sample CSV - Vehicle.csv:
vehicleName(STRING),averageDistance(DOUBLE)
"Sedan",11234.56
"Truck",56789.01
"Compact",23456.78
DECIMAL¶
The DECIMAL data type in Backendless is specifically designed for high-precision arithmetic and storage of numerical values where precision beyond what is offered by DOUBLE is required. It is particularly useful for applications involving financial calculations, scientific data where exactitude is critical, and any other domain requiring precise representation of decimal numbers without rounding errors. Compared to DOUBLE, the DECIMAL data type offers superior precision by allowing developers to explicitly define the scale (the number of digits after the decimal point) and the overall size (the total number of digits). This makes DECIMAL an excellent choice for applications that cannot tolerate rounding errors or precision loss, such as financial applications, precise measurement record-keeping, or any scenario where the exactness of numerical data is paramount. Utilizing the DECIMAL type ensures that your Backendless application can handle complex numerical data with the fidelity required by your specific use case, enhancing data accuracy and application reliability.
For the basic use of the data type, the format in a CSV file is:
ColumnName(DECIMAL)
A complete declaration of the data type is:
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""DECIMAL"",
""dataSize"" :data size value,
""decimalScale"" :scale value
""validator"" :""regex"",
""defaultValue"" :""value"",
""dynamicProps"" :{""description"":""Some description""}
})"
See the parameter descriptions in the general section above except ""dataSize"" and ""decimalScale"" which apply only to the DECIMAL data type:
| Argument | Description |
|---|---|
""dataSize"" |
Defines the maximum number of digits that can be stored in the column, including both sides of the decimal point. |
""decimalScale"" |
Indicates the maximum number of digits that can appear after the decimal point, crucial for maintaining precision. |
Sample CSV - Accounts.csv:
accountName(STRING),"balance({""type"":""DECIMAL"",""dataSize"":7,""decimalScale"":2})"
"John Doe",12345.67
"Jane Smith",89012.45
"Alex Johnson",56789.01
MONEY¶
The MONEY data type in Backendless is a specialized format designed to optimize the handling and visualization of financial values within the platform. While it functions as a visual derivative of the DECIMAL type, its primary distinction lies in how it is presented and interacted with through various Backendless user interfaces, such as the Data Browser, visualizations, and certain components in the UI Builder. Internally, the MONEY data type is managed identically to the DECIMAL type, ensuring precise arithmetic and storage of financial data with fixed-point precision. This means it benefits from the DECIMAL type's capacity to accurately represent numbers with significant decimal precision, which is essential for financial calculations to avoid rounding errors. The key advantage of the MONEY data type is in its presentation layer within Backendless. User interfaces recognize MONEY fields and may format these values in a way that's more intuitive for financial data, such as adding currency symbols, formatting numbers according to locale-specific rules, or displaying values in a more readable format for end-users.
Extended declaration (must be in a single line in the header row of the imported CSV):
"moneyColumnName({
""constraints"" :[""NN"",""IDX""],
""type"" :""DECIMAL"",
""dataSize"" :10,
""decimalScale"" :2,
""validator"" :""regex"",
""defaultValue"" :""value"",
""dynamicProps"" :{""localData"":{""type"":""MONEY""},""description"":""test""}
})"
BOOLEAN¶
The BOOLEAN data type is a fundamental component in Backendless for representing binary data, essentially capturing true/false or yes/no values. This data type is particularly useful for flags, status indicators, and any other scenarios where a simple binary choice is required to describe the state or condition of an entity within your application. When importing data through CSV files into Backendless, the declaration of a BOOLEAN column can be as simple as:
ColumnName(BOOLEAN)
or enriched with various configurations to suit your application's needs. Notice the extended column configuration also supports visualization options which apply to how the boolean data is rendered in Backendless Console and Visualizations:
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""BOOLEAN"",
""dataSize"" :1,
""defaultValue"" :""true or false"",
""dynamicProps"" :{""localData"":{""visualizationType"":""visualization type""}, ""description"":""Some description""}
})"
where:
| Argument | Description |
|---|---|
""dataSize"" |
- Must be set to 1. |
- ""visualizationType"" - Optional parameter, if specified instructs Backendless to visualize boolean data in the column as shown in the "New Column" popup in the Backendless Console when the data type is set to BOOLEAN. See the "Visualize As" section. The property value in the CSV file must be set to one of the following values:
""TRUE_FALSE"",""TOGGLE"",""YES_NO"",""CHECKBOX""
Sample CSV - Tasks.csv:
taskName(STRING),isCompleted(BOOLEAN)
"Install software",true
"Update database",false
"Backup files",true
DATETIME¶
The DATETIME data type in Backendless is essential for representing points in time, combining both date and time elements into a single value. This capability is crucial for applications that require tracking events, scheduling activities, or recording timestamps for changes or transactions. The DATETIME type ensures precise timekeeping and enables temporal queries, comparisons, and calculations. When importing data via CSV files, the declaration for a DATETIME column can be in the simplified format:
ColumnName(BOOLEAN)
or detailed to include various settings that define its behavior and characteristics within the database:
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""DATETIME"",
""validator"" :""regex"",
""defaultValue"" :""YYYY-MM-dd HH:mm:ss"",
""dynamicProps"" :{""description"":""Some description""}
})"
See the parameter descriptions in the general section. Values in a CSV file must be in any of the documented formats.
Sample CSV - Documents.csv:
entryTitle(STRING),creationDateTime(DATETIME)
"Quarterly Report","2023-10-01T09:00Z"
"Project Plan","2023-10-02T14:30Z"
"Meeting Notes","2023-10-03T11:15Z"
TEXT¶
The TEXT data type in Backendless is designed to accommodate large quantities of textual data, supporting content up to 20,000 characters. This capacity significantly exceeds that of the STRING data type, which is typically limited to shorter text entries, making TEXT ideal for storing extensive passages of text such as articles, product descriptions, user feedback, or any detailed information that requires more space than what STRING can offer. Declaration of the TEXT columns uses the standard approaches without introducing any new properties:
Basic declaration:
ColumName(TEXT)
The extended version of the supported syntax is (make sure the entire declaration in a CSV file is in a single line). Notice the declaration for the TEXT data type does not support the dataSize and defaultValue parameters:
"ColumnName({
""constraints"" :[""NN"",""IDX"",""UQ""],
""type"" :""TEXT"",
""validator"" :""regex"",
""dynamicProps"" :{""description"":""Some description""
}})"
Sample CSV - Products.csv:
productName(STRING),productDescription(TEXT)
"Coffee Maker","The Coffee Maker model X1000 features an innovative design with a built-in grinder, programmable settings, and a thermal carafe to keep your coffee hot for hours. Ideal for coffee enthusiasts looking for convenience without compromising on quality."
"Smartphone","The latest Galaxy SuperPhone offers a sleek design, a 6.8-inch high-definition display, and a powerful camera system capable of capturing stunning photos and videos. With 5G connectivity, enjoy blazing-fast internet speeds wherever you go."
"Laptop","This UltraBook laptop combines portability with performance. Equipped with a high-resolution 14-inch display, a durable battery lasting over 12 hours, and a lightweight design, it's perfect for professionals on the move."
FILE REFERENCE¶
The FILE REFERENCE (FILE_REF) data type in Backendless is specifically designed to create associations between database records and files by storing file references as URLs. This functionality is pivotal for applications that handle multimedia content, documents, or any form of external files, enabling a seamless link between the database entries and the files stored either in the Backendless file storage associated with your application or on external servers.
Basic declaration:
ColumName(FILE_REF)
Extended declaration (must be on a single line in the CSV's header row):
"ColumnName({
""constraints"" :[""NN"",""IDX""],
""type"" :""FILE_REF"",
""dataSize"" :500,
""defaultValue"" :""/someDir/someFile.html"",
""dynamicProps"" :{""description"":""some description""}})"
where:
| Argument | Description |
|---|---|
""dataSize"" |
This property defines the maximum length of the URL stored in a FILE_REF column. It ensures that the URL, whether absolute or relative, fits within the specified limit, maintaining database integrity and preventing errors related to data overflow. |
""defaultValue"" |
Specifies a default URL to be used when a new record is created without an explicit value for the FILE_REF column. This can be particularly useful for default images, documents, or any standard file that should be associated with new records automatically. |
Sample CSV - Products.csv:
productName(STRING),productImage(FILE_REF)
"Coffee Maker",files/images/coffeemaker.jpg
"Smartphone",files/images/smartphone.jpg
"Laptop",https://examplestorage.com/images/laptop.jpg
Notice the first two file references are relative URLs. For these URLs, Backendless assumes the files will be available at the specified paths in the File storage associated with the application. The complete, absolute URL for the files will be calculated based on the hostname used in the API call to retrieve database records.
JSON¶
The JSON data type in Backendless is designed to accommodate the storage of structured, arbitrary JSON data directly within database records. This flexibility is crucial for applications that deal with complex data structures, need to store configuration settings, serialized objects, or any form of nested data that doesn't fit neatly into traditional relational database columns. The JSON data type supports a wide range of use cases, from storing user preferences and settings to capturing detailed object metadata or complex hierarchical data structures. JSON data stored in Backendless can be queried and manipulated, offering powerful tools for searching within JSON fields and integrating this data seamlessly into application logic.
Basic declaration:
ColumName(JSON)
Extended declaration (must be on a single line in the CSV's header row). Notice the declaration does not support the ""dataSize"" and ""defaultValue"" properties:
"ColumnName({
""constraints"" :[""NN""],
""type"" :""JSON"",
""dynamicProps"" :{""description"":""some description""}})"
Sample CSV - SampleValues.csv:
sampleJSON(JSON),type(STRING)
"[1, 2, 3, 4, 5]","array of ints"
"{""make"": ""BMW"", ""model"": ""IX"", ""mileage"": 123456}","object"
"12345","number"
"[""one"", ""two"", ""three""]","array of strings"
"""Hello World!""","string"
AUTO NUMBER/AUTO INCREMENT¶
The AUTO_INCREMENT data type in Backendless plays a crucial role in maintaining sequential order and uniqueness for record identification. When employing the AUTO_INCREMENT data type in a column and importing data via a CSV file, an important operational detail comes into play regarding the assignment of new values post-import. Once the CSV file has been successfully imported into the Backendless database, the mechanism for assigning new values to the AUTO_INCREMENT column is intelligently designed to ensure continuity and uniqueness. The next value that will be automatically assigned to this column for any newly created record is calculated based on the highest integer value present in the imported data for that column. This means that Backendless automatically identifies the maximum integer value that was imported into the AUTO_INCREMENT column and increments from that value forward for subsequent record insertions. This approach guarantees that each record receives a unique, sequentially incremented identifier, regardless of the dataset initially imported.
Basic declaration:
ColumName(AUTO_INCREMENT)
Extended declaration:
"ColumnName({
""constraints"":[""UQ"",""IDX""],
""type"":""AUTO_INCREMENT"",
""dynamicProps"":{""localData"":{},""description"":""some description""}
})"
MULTIPLE CHOICE¶
The "multiple choice" data type in Backendless is an advanced adaptation of the traditional STRING data type, crafted to enhance user interaction and data representation within the platform. This data type is specifically designed to handle scenarios where a predefined set of options is presented for selection, adding a layer of visual and functional richness to the handling of choice-based data.
Features and Capabilities
- Predefined Values and Labels: Allows for the specification of a fixed list of choices, each associated with a label for easy identification and display within the Backendless Console's Data Browser, Visualizations, and UI Builder. This feature facilitates clear and concise representation of options available for a given field.
- Validation of Values: Offers optional validation for inserted or updated values through API calls, ensuring that data integrity is maintained by restricting input to the defined set of choices.
- Multiple Selections: Unlike a simple
STRINGfield, the "multiple choice" data type can be configured to allow users to select more than one option from the predefined set, enabling versatility in data capture for fields requiring multi-select capabilities. - Color-Coding: Enhances the visual representation of choices by assigning distinct colors to each option. This feature is particularly useful in Data Browser, Visualizations, and UI Builder, where color-coded values can quickly convey additional meaning or categorization to users at a glance.
Column declaration (must ne in a single line in the header row in the CSV file):
"ColumnName({
""constraints"":[""UQ"",""NN"",""IDX""],
""type"":""STRING"",
""dataSize"":250,
""validator"":""^((Austin|Sacramento){1})(,(Austin|Sacramento){1})*$"",
""dynamicProps"":{
""localData"":{
""type"":""MULTIPLE_CHOICE"",
""multipleChoice"":{
""rules"":{
""isColored"":true,
""isValueLabel"":true,
""sortDirection"":null OR ""desc"" or ""asc"",
""useValidation"":true,
""isMultipleSelection"":true
},
""options"":[
{
""id"":""bbf798a4-9ffc-7e07-2c82-d6db84687a27"",
""color"":""#7051b8"",
""label"":""Texas"",
""value"":""Austin""
},
{
""id"":""1487be22-c391-e762-3a36-465252cf311d"",
""color"":""#2acb01"",
""label"":""California"",
""value"":""Sacramento""
}
]
}
}
}
})"
where:
| Argument | Description |
|---|---|
""dataSize"" |
Specifies the maximum length of the value that can be stored in the column. For columns configured to allow multiple selections, the ""dataSize"" should accommodate the combined length of all selectable options. It's important to note that the underlying STRING data type has a limit of 500 characters. |
""validator"" |
This property, when defined, should include a regular expression (regex) that validates the input against the possible combinations of labels and their corresponding values. This ensures that only permissible selections are made. |
""type"" |
This should be set to """MULTIPLE_CHOICE"" to indicate the column uses the multiple selection data type. |
""rules"" |
Dictates how the data type behaves and is represented within Backendless, including in the Data Browser, Visualizations, and UI Builder. The rules include:""isColored"": When true, enables color-coding for the selection options based on the colors defined in the options. This visually distinguishes each choice.""isValueLabel"": Configures the display to use a combination of value and label (true) or to use the value for both (false).""sortDirection"": Controls the sorting order of the options; can be null (no sorting), "desc" for descending, or "asc" for ascending order.""useValidation"": If set to true, Backendless enforces the validation rule specified in the validator, restricting column entries to the defined options.""isMultipleSelection"": Allows users to select more than one option from the predefined set in Data Browser, Visualizations, and UI Builder, enhancing flexibility in data entry and presentation. |
""options"" |
A JSON array comprising objects that detail the available choices for the column. Each object within the array should specify a ""label"", ""value"", and ""color"", defining the textual display, underlying value, and visual representation of each option, respectively. There must also be the ""id"" property which is a unique identifier (a UUID) of the option. |
COLOR¶
The COLOR data type in Backendless offers a specialized way to store and manipulate color values, serving as an extension of the STRING data type but specifically tailored for hexadecimal RGB color codes. This data type is designed not only to facilitate the storage of color information within the Backendless database but also to enhance the interaction and visualization of color data across various Backendless interfaces, including the Data Browser in the Backendless Console, Visualizations, and UI Builder. The COLOR data type is intended for storing color values in the standard hexadecimal format, allowing for precise representation of colors. Backendless recognizes the COLOR data type and provides special handling in its visual interfaces. This includes more intuitive displays and interactions when viewing or editing color values, ensuring a user-friendly experience. When defining a COLOR column in CSV import files, the data type supports expressive syntax that allows specifying how the color data should be presented and interacted with in the Backendless platform.
Below you will find various data type configuration options. These options correspond to various visualizations the COLOR data type may have. Notice that the ""visualizationType"" property may have a value of either ""RECTANGLE"" or ""CIRCLE"".
"Millions of colors": Provides a comprehensive color selection tool with a wide range of colors.
"ColumnName({
""constraints"":[],
""type"":""STRING"",
""dataSize"":50,
""defaultValue"":""#someRGBvalue"",
""dynamicProps"":{
""localData"":{
""type"":""COLOR_PICKER"",
""colorPicker"":{
""selectedColors"":[],
""colorPickerType"":""CHROME"",
""visualizationType"":""RECTANGLE"" OR ""CIRCLE""
}
},
""description"":""some desc""
}
})",
This options corresponds to the following column configuration: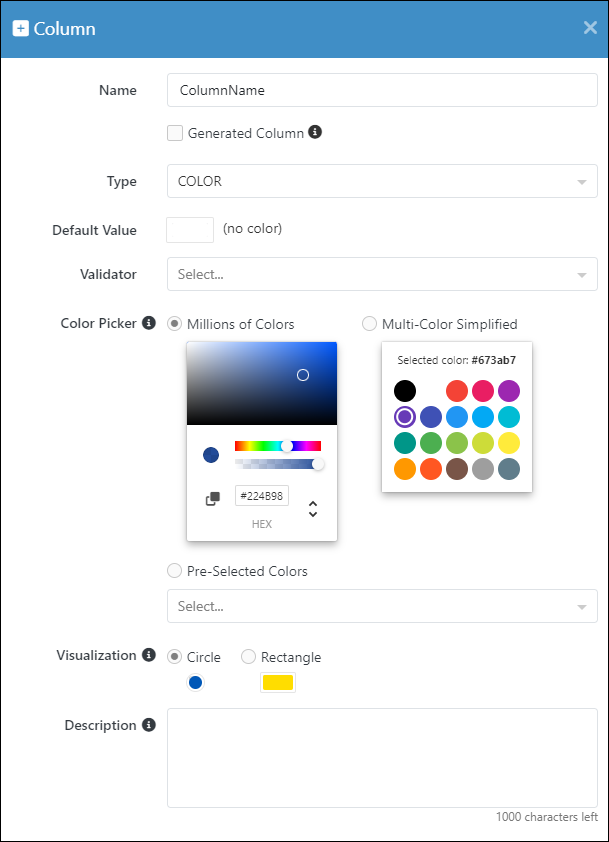
"Multi-color simplified": Offers a simplified interface for choosing colors, balancing variety and simplicity.
"multiColorSimlifiedRect({
""constraints"":[],
""type"":""STRING"",
""dataSize"":50,
""defaultValue"":""#someRGBvalue"",
""dynamicProps"":{
""localData"":{
""type"":""COLOR_PICKER"",
""colorPicker"":{
""selectedColors"":[],
""colorPickerType"":""MATERIAL"",
""visualizationType"":""RECTANGLE"" OR ""CIRCLE""
}
},
""description"":""some description""
}
})",
Data type declaration above corresponds to the following Color Picker configuration: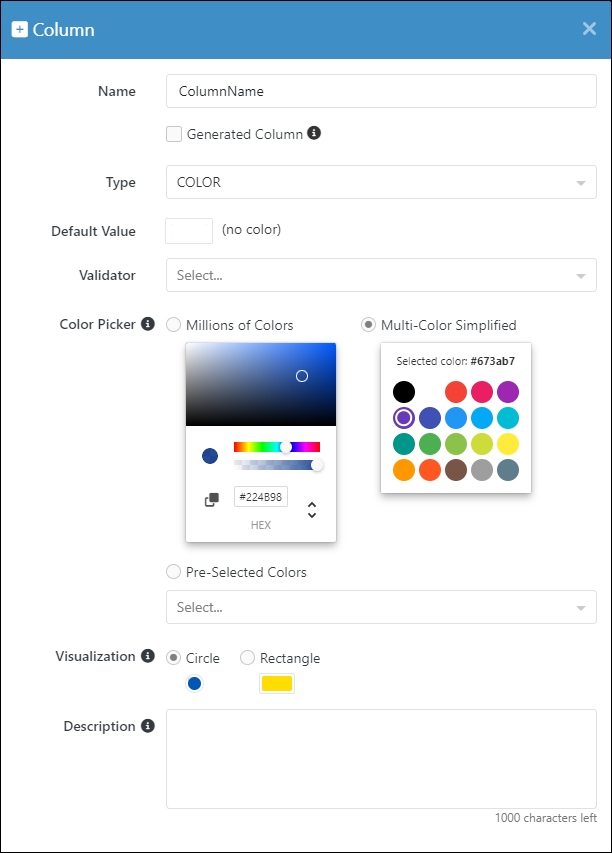
"Pre-selected colors": Limits selections to a predefined set of colors, streamlining the choice process for specific use cases.
"preSelectedColorsCircle({
""constraints"":[],
""type"":""STRING"",
""dataSize"":50,
""dynamicProps"":{
""localData"":{
""type"":""COLOR_PICKER"",
""colorPicker"":{
""selectedColors"":[
{""label"":""Brown"",""value"":""#795548""},
{""label"":""Red"",""value"":""#f44336""},
{""label"":""White"",""value"":""#ffffff""},
{""label"":""Black"",""value"":""#000000""},
{""label"":""Purple"",""value"":""#9c27b0""},
{""label"":""Indigo"",""value"":""#3f51b5""},
{""label"":""Blue"",""value"":""#2196f3""},
{""label"":""Pink"",""value"":""#e91e63""},
{""label"":""Cyan"",""value"":""#00bcd4""},
{""label"":""Teal"",""value"":""#009688""},
{""label"":""Green"",""value"":""#4caf50""},
{""label"":""Lime"",""value"":""#cddc39""},
{""label"":""Yellow"",""value"":""#ffeb3b""},
{""label"":""Orange"",""value"":""#ff9800""},
{""label"":""Grey"",""value"":""#9e9e9e""}
],
""colorPickerType"":""SELECTOR"",
""visualizationType"":""RECTANGLE"" OR ""CIRCLE""
}
}
}
})",
Data type configuration above corresponds to the color picker configuration that has a pre-defined set of available colors: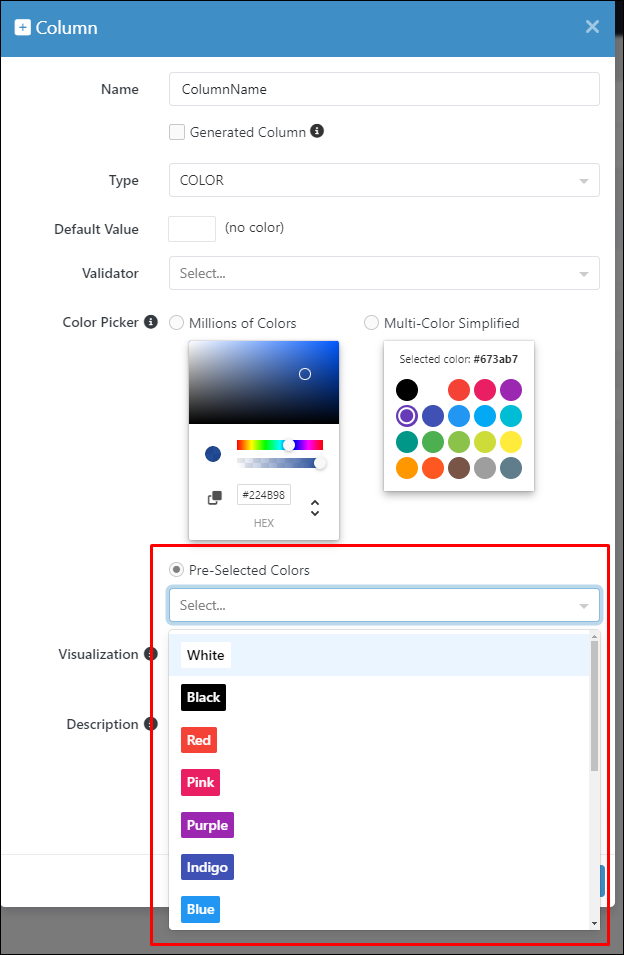
Relations¶
Backendless supports import of related records. This means you can import data into the Backendless database where a single record in one table may reference one or more records in another table. There are two types of relations supported by the system: one-to-one and one-to-many. The former establishes a cardinality between the records where one record in one table references one and only one record in another table. The latter establishes a cardinality where one record in one table can reference multiple records in another table. An example of a one-to-one cardinality are Country-Capital or Product-Manufacturer relations. Some examples of the one-to-many are Country-City or Order-Item relations.
One-to-one Relations¶
When importing relational data into Backendless, understanding how to correctly declare relation columns in CSV files is crucial. This process is key to linking tables together within your Backendless database, ensuring data integrity and enabling seamless interaction between related datasets. Consider the diagram below. It illustrates a relationship between two tables - Country and City. In this example, the Country table includes a one-to-one relation column named "capital," which references the City table. The meaning of that relation column is that for every record stored in the Country table, the column may contain a "reference" or a pointer to a record in the City table.
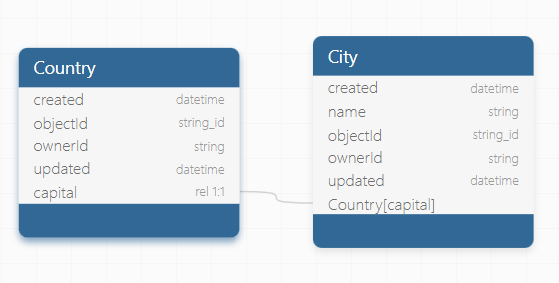
To accurately replicate these tables and their relationship in Backendless via CSV import, adhere to the following guidelines:
- Begin by preparing two separate CSV files named Country.csv and City.csv, each representing a table within Backendless.
- In the Country.csv file, the header row must include a declaration for the relation column. For a one-to-one relationship with the "City" table, such as a "capital" column in the "Country" table, this declaration is essential for establishing the connection between the two tables.
- Within Country.csv, each record that requires a link to a "City" record should have the relation column (capital in this example) filled with the objectId of the corresponding record from City.csv. The objectId serves as a unique identifier, acting as a "reference" or "pointer" to the related record in the "City" table.
Below is a general format for declaring a one-to-one relation column in CSV's header row. The declaration must be in a single line.
"ColumnName({
""constraints"":[""UQ""],
""type"":""RELATION"",
""relatedTable"":""Name of the related table"",
""relationIdentificationColumn"":""column name"",
""dynamicProps"":{
""description"":""some description""
}
})"
To put it in the context, the declaration of the relation "capital" column in Country.csv would look as shown below (on a single line):
"capital({
""constraints"":[""UQ""],
""type"":""RELATION"",
""relatedTable"":""City"",
""relationIdentificationColumn"":""name"",
""dynamicProps"":{
""description"":""some description""
}
})"
where:
| Argument | Description |
|---|---|
""constraints"" |
Use the ""UQ"" (Unique) constraint only if the related record must be unique for each corresponding parent. For example, a city cannot be the capital of two different countries, therefore the ""UQ"" constraint makes sense here. |
""type"" |
Must be set to ""RELATION"". |
""relatedTable"" |
Name of the related table. |
""relationIdentificationColumn"" |
This optionally sets the name of the column from the related table which will be used to show a value from the related record in Backendless Console. |
Example of CSV Header and Data Row
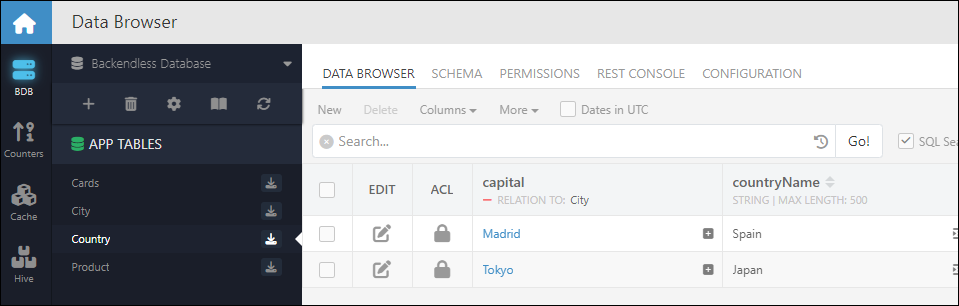
For City.csv, assume a simple structure with an objectId and city names:
objectId,name
1,Madrid
2,Tokyo
In Country.csv, the relation column is included in the header, and the data row references the objectId from City.csv:
countryName,"capital({""constraints"":[""UQ""],""type"":""RELATION"",""autoLoad"":false,""relatedTable"":""City"",""relationIdentificationColumn"":""name""})"
Spain,1
Japan,2
When importing files with related records, make sure to select all "interconnected" CSV files:
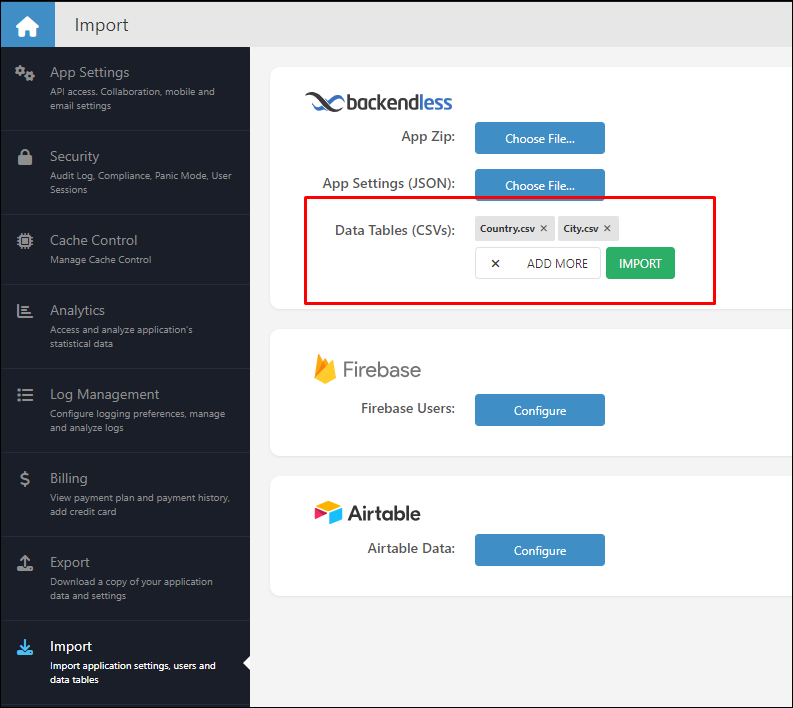
Backendless recognizes relations and displays them accordingly on the second step of the data import:
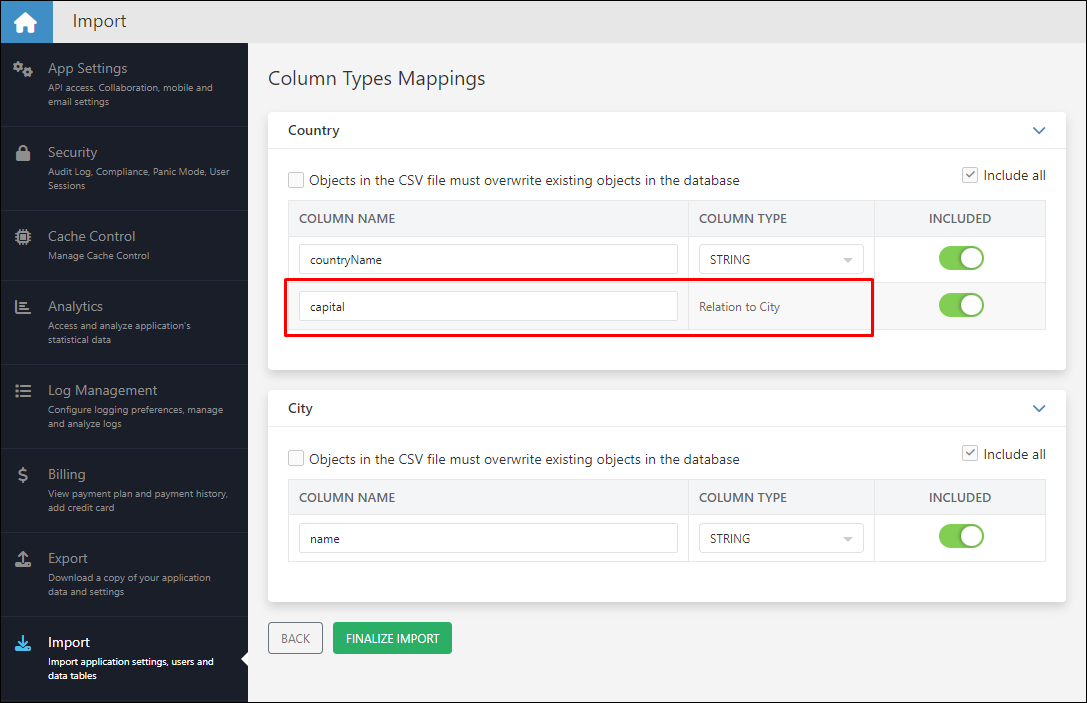
Once the import is complete, you can see the imported data with relations:
One-to-many Relations¶
When setting up one-to-many (1:N) relationships between tables in Backendless via CSV import, understanding the correct approach to declaring relation columns is essential. This setup allows a single record in one table (the "one" side) to reference multiple records in another table (the "many" side). Take the relationship between the "Country" and "City" tables as an example. In this scenario, the "Country" table has a column called "cities," indicating that a country can be associated with multiple cities.
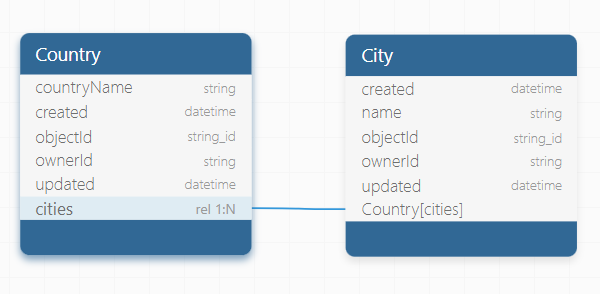
The declaration process for one-to-many relationships in CSV files differs from that of one-to-one relationships. For one-to-many relationships, the declaration is made in the CSV file of the "child" table, which represents the "many" part of the relationship. Here's how the column should be declared in the CSV header:
"ColumnName({
""constraints"":[""UQ""],
""type"":""RELATION_LIST"",
""relatedTable"":""Parent Table Name"",
""dynamicProps"":{""localData"":{},""description"":""come description""}})"
This declaration should be placed on a single line in the header row of the child table's CSV file. The column values should consist of the objectId value of the "parent" record from the referenced ""relatedTable"".
For a clearer understanding, consider the structure of the following CSV files:
Country.csv:
countryName(STRING),objectId(STRING_ID)
Spain,1
Japan,2
City.csv:
name(STRING),objectId(STRING_ID),"cities({""type"":""RELATION_LIST"",""relatedTable"":""Country""})"
Madrid,1,1
Barcelona,2,1
Tokyo,3,2
Osaka,4,2
In this example, cities are linked to their respective countries by the objectId of the country record, demonstrating the one-to-many relationship from countries to cities.
During the import process into Backendless, a summary of column type mappings is displayed, confirming the successful creation and configuration of relation columns based on the declarations in the CSV files. Although the cities column is declared in the City.csv, it logically appears in the "Country" table to represent the one-to-many relationship accurately.
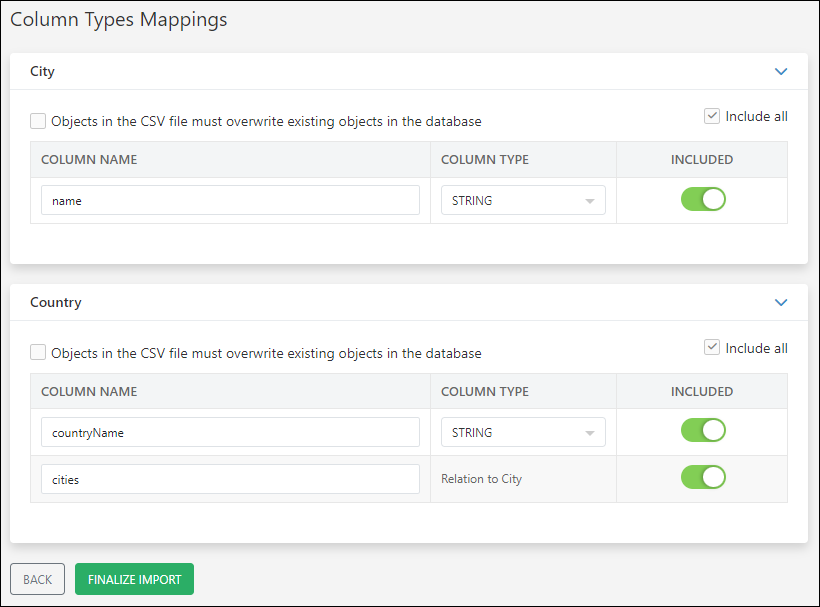
Once the import is finalized, you can see the imported data with all the relations between the records in Data Browser:
Cities:
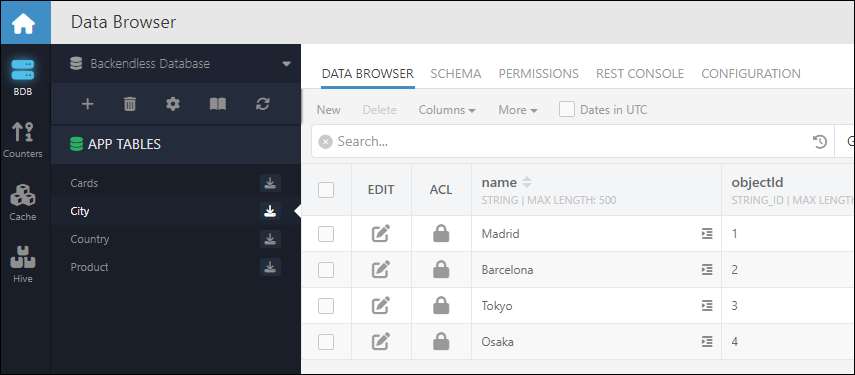
Countries:
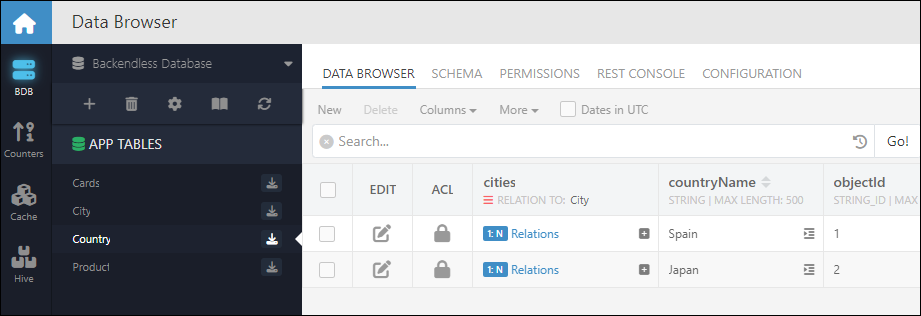
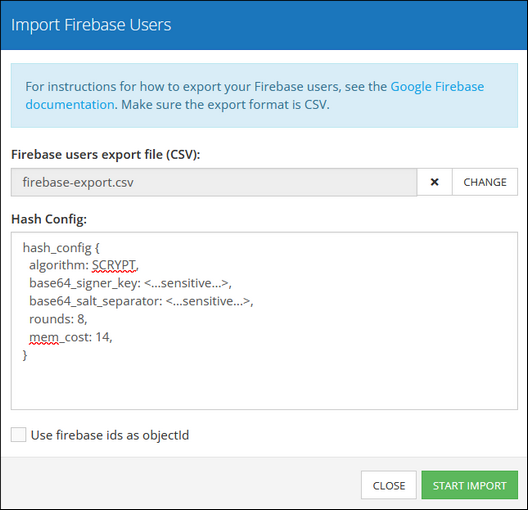
Firebase Users¶
The Firebase Users section expects a .csv data table exported from the Google Firebase. For more information about exporting user data from the Firebase and hash configurations, refer to the official documentation.
When clicking the Configure button, the corresponding menu will prompt you to select the destination folder where the .csv file is stored in your computer, You must also paste the hash configuration into the Hash Config field to process password hashes of the imported users: