AI Audio Transcription Plugin
In the rapidly evolving world of digital content and communication, seamless integration between audio and text is becoming increasingly paramount. Recognizing this demand, we’re offering the AI-powered Audio Transcription API. This advanced service leverages state-of-the-art machine-learning techniques to generate a prompt-driven transcription of audio files, turning spoken words into readable text, and unlocking a host of new possibilities for businesses and developers alike.

Usage Examples and Use-Cases
- Content Creation and Journalism:
Journalists and content creators can now instantly transcribe interviews, podcasts, and videos. No longer will hours be wasted on manual transcription. This allows for faster content generation and streamlined workflows. - Business Meetings and Conferences:
Imagine having a detailed, searchable record of every meeting or conference call, ready for review moments after it ends. Our API enables businesses to keep thorough records without additional manpower. - Educational Institutions:
Educators and students can benefit from instant transcriptions of lectures, seminars, and study groups, making note-taking a breeze and ensuring no vital information is missed. - Customer Service Enhancement:
Call centers and customer service departments can use the API to transcribe calls for training, quality assurance, and compliance purposes, offering a way to continually improve their services. - Health and Legal Sectors:
Doctors dictating patient notes or attorneys recording client interactions can utilize our API for accurate, immediate transcription, ensuring meticulous records are kept.
These are just a few examples of how the Audio Transcription API Plugin can be applied in real-world scenarios to enhance communication, accessibility, and user experience for various industries and applications.
Our API is designed with ease of integration in mind, ensuring developers can effortlessly incorporate it into their applications. It supports various audio formats and languages, ensuring versatility and global applicability. We encourage developers and businesses to tap into this transformative tool, ushering in an era of enhanced communication and content creation. Whether you’re a software engineer aiming to integrate this functionality into your apps or a business owner looking to leverage AI-powered transcription for operational improvements, our API is here to serve your needs.
Installation Instructions
- Login to Backendless Console and select your app. Open the Marketplace screen, select the API Services section, and install the OpenAI Audio Transcription Plugin.
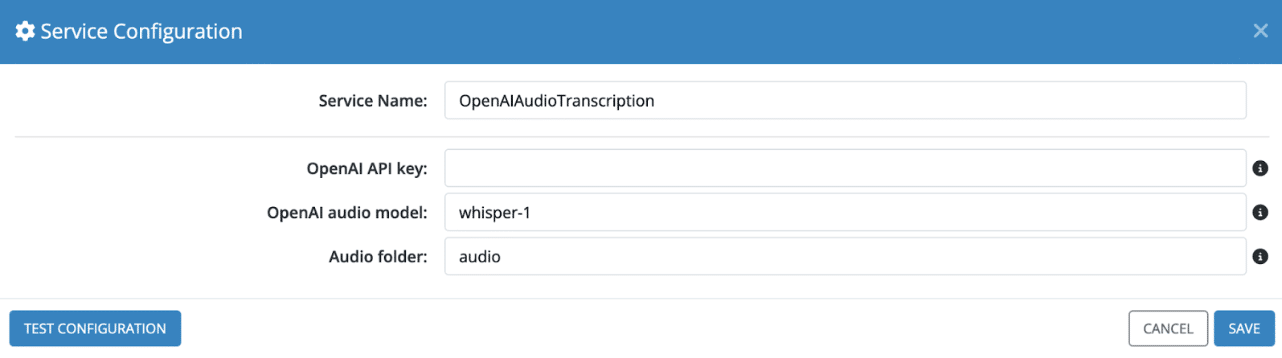
- During the installation, you are prompted to enter your
OpenAI API key,OpenAI audio model, andAudio folder. Enter the required details and click the Save button:
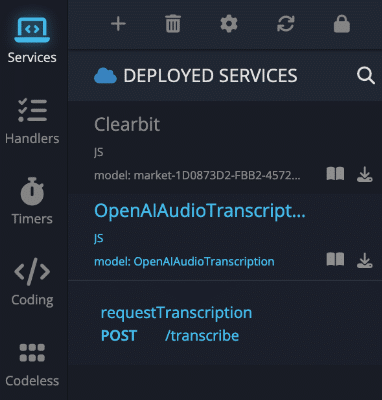
- To verify the installation, click the Cloud Code icon in the Backendless Console and confirm that the OpenAIAudioTranscription API service appears in the list of services:
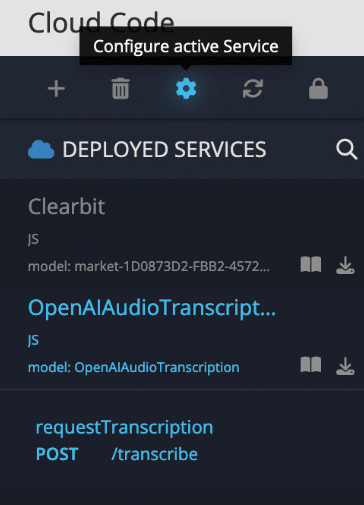
- If you need to change any of the configuration settings (API key, OpenAI audio model, or the default folder for the audio files), click the gear icon to access the Service Configuration popup.
Service Method(s)
There is only one method in this service – requestTranscription. This method transcribes an audio file in any language to English.
Method:
POST
Endpoint URL:
https://xxxx.backendless.app/api/services/OpenAIAudioTranscription/transcribe
The xxxx.backendless.app is a subdomain assigned to your application. For more information, see the Client-side Setup section of the Backendless documentation.
Request Headers:
Content-Type:application/json
Request Body:
The request body must be a JSON object with the structure shown below:
{
"audioFileUrl": "string",
"model": "string",
"prompt": "string",
"language": "string",
"responseFormat": "string",
"temperature": 0,
"saveSource": false
}
Parameters explanation:
audioFileUrl– Required. Url to an audio file in one of these formats:flac,mp3,mp4,mpeg,mpga,m4a,ogg,wav, orwebm.model– Optional. Name of an OpenAI model. For the list of available models refer to https://platform.openai.com/docs/models/overview. Only audio models can be used in this service,whisper-1is set as the default.prompt– Optional. A text to guide the model’s style or continue a previous audio segment. The prompt should be in English.language– Optional. The language of the input audio. Supplying the input language in ISO-639-1 format will improve accuracy and latency.responseFormat– Optional. The format of the transcript output, in one of these options:JSON,text,srt,verbose_json, orvtt.JSONis used by default.temperature– Optional. The sampling temperature. The value must be between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. If set to 0, the model will use log probability to automatically increase the temperature until certain thresholds are hit.saveSource– Optional. Defaults tofalse. If the parameter is totrue, the service will save the input source file from theaudioFileUrlparameter in the Backendless file storage. The file will be saved in a folder specified during the service installation.
Response Body:
Returns translation in specified “responseFormat” value, JSON by default.
Example:
curl -X "POST" "https://xxx.backendless.app/api/services/OpenAIAudioTranscription/transcribe" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d $'{
"audioFileUrl": "https://xxx.backendless.app/api/files/audio/export_111.mp3",
"responseFormat": "json",
"temperature": 0.5,
"saveSource": false
}'
Response:
{
"text": "OpenAI's Transcription API can be valuable in various use case scenarios for converting spoken language into written text."
}
Codeless Reference
